ChatGPT
以下是OpenAI对训练ChatGPT所使用方法的简单描述:
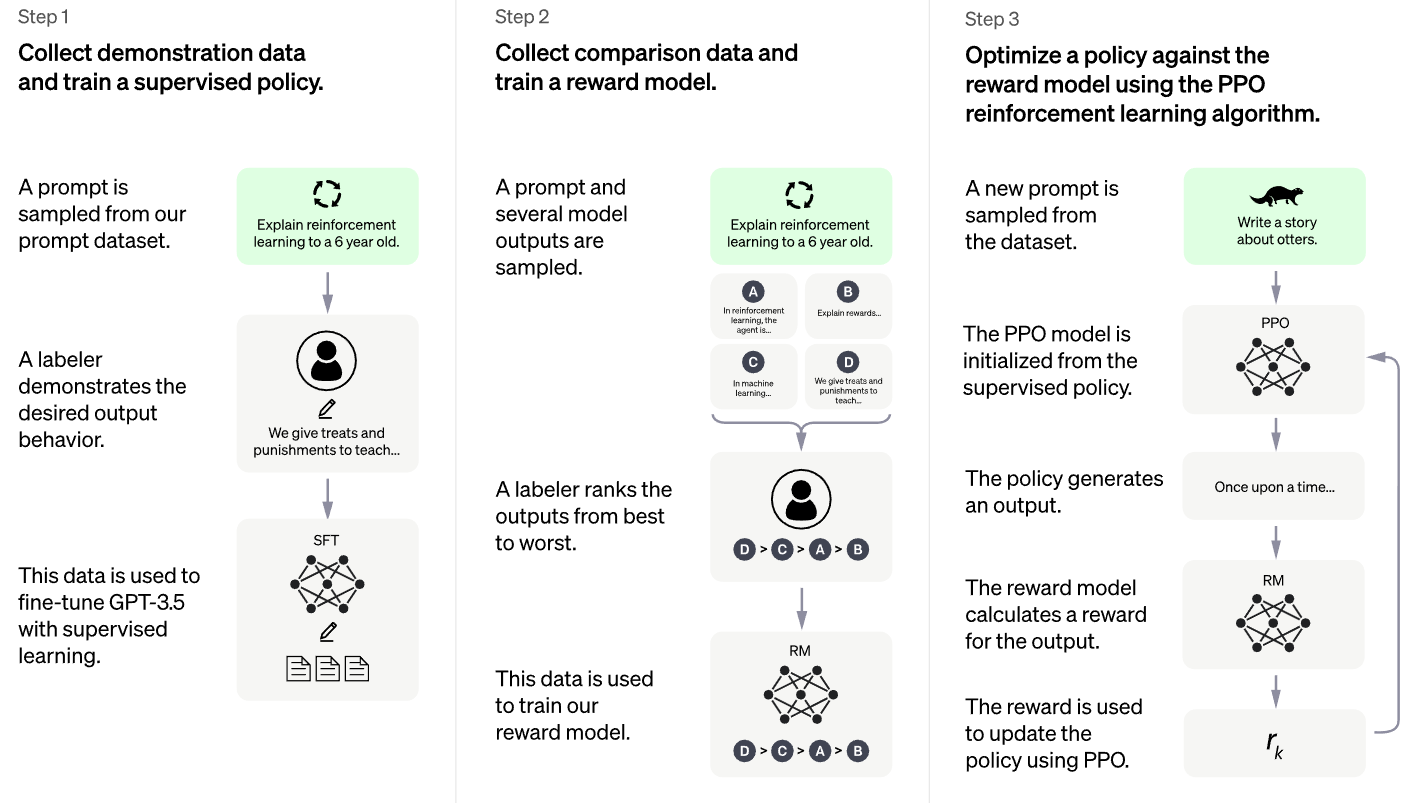
We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup. We trained an initial model using supervised fine-tuning: human AI trainers provided conversations in which they played both sides—the user and an AI assistant. We gave the trainers access to model-written suggestions to help them compose their responses. We mixed this new dialogue dataset with the InstructGPT dataset, which we transformed into a dialogue format.
To create a reward model for reinforcement learning, we needed to collect comparison data, which consisted of two or more model responses ranked by quality. To collect this data, we took conversations that AI trainers had with the chatbot. We randomly selected a model-written message, sampled several alternative completions, and had AI trainers rank them. Using these reward models, we can fine-tune the model using Proximal Policy Optimization. We performed several iterations of this process.
根据OpenAI的描述,ChatGPT采用的是Reinforcement Learning from Human Feedback (RLHF)方法对模型进行训练,下面是DataWhale开源社区关于强化学习的代码仓库,便于进行相关知识的学习:github
关于ChatGPT
ChatGPT是Transformer和GPT等相关技术发展的集大成者。总体来说,ChatGPT的性能卓越的主要原因可以概括为三点:
- 使用的机器学习模型表达能力强。
- 训练所使用的数据量巨大。
- 训练方法的先进性。
一 机器学习模型
基于文法的模型
这个阶段主要思路就是利用语言学家的智慧尝试总结出一套自然语言文法,并编写出基于规则的处理算法进行自然语言处理。我们熟悉的编译器也是通过这种方法将高级语言编译成机器语言的。可惜的是,自然语言是极其复杂的,基本上不太可能编写出一个完备的语法来处理所有的情况,所以这套方法一般只能处理自然语言一个子集,距离通用的自然语言处理还是差很远。
基于统计的模型
在这个阶段,大家开始尝试通过对大量已存在的自然语言文本(我们称之为语料库)进行统计,来试图得到一个基于统计的语言模型。比如通过统计,肯定可以确定“吃”后面接“饭”的概率肯定高于接其他词如“牛”的概率,即P(饭|吃)>P(牛|吃)。
虽然这个阶段有很多模型被使用,但是本质上,都是对语料库中的语料进行统计,并得出一个概率模型。一般来说,用途不同,概率模型也不一样。不过,为了行文方便,我们接下来统一以最常见的语言模型为例,即建模“一个上下文后面接某一个词的概率“。刚才说的一个词后面接另一个词的概率其实就是一元语言模型。
模型表达能力
模型表达能力简单来说就是模型建模数据的能力,比如上文中的一元语言模型就无法建模“牛吃草”和“我吃饭”的区别,因为它建模的本质统计一个词后面跟另一个词的概率,在计算是选“草”还是选“饭”的时候,是根据“吃”这个词来的,而“牛”和“我”这个上下文对于一元语言模型已经丢失。
模型参数数量
有人说,既然如此,为啥我们不基于更多的上下文来计算下一个词的概率,而仅仅基于前一个词呢?OK,这个其实就是所谓的n元语言模型。总体来说,n越大,模型参数越多,表达能力越强。当然训练模型所需要的数据量越大(显然嘛,因为需要统计的概率的数量变多了)。
模型结构
然而,模型表达能力还有另一个制约因素,那就是模型本身的结构。对于基于统计的n元语言模型来说,它只是简单地统计一个词出现在一些词后面的概率,并不理解其中的各类文法、词法关系,那它还是无法建模一些复杂的语句。比如,“我白天一直在打游戏”和“我在天黑之前一直在玩游戏“两者语义很相似,但是基于统计的模型却无法理解两者的相似性。因此,就算你把海量的数据喂给基于统计的模型,它也不可能学到ChatGPT这种程度。
基于神经网络的模型
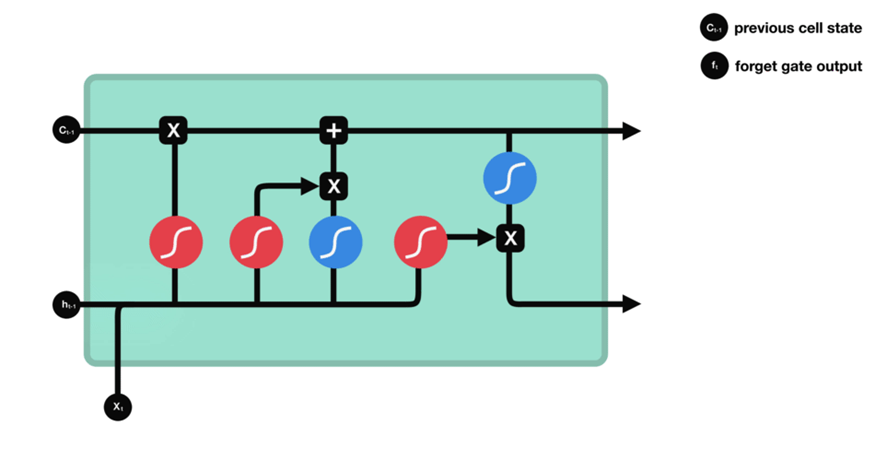
RNN & LSTM
下面我们要用魔法打败魔法:

Attention Mechanisms

Transformer
ChatGPT所依赖GPT3.5语言模型的的底层正是Transformer。
二 训练数据
训练数据和模型之间是紧密相关的。训练数据是用来训练机器学习模型的输入数据,而模型则是对这些数据进行处理和学习的算法或函数。
在机器学习中,训练数据通常包括输入数据和相应的输出或标签。输入数据可以是各种形式的数据,如图像、文本、声音等。输出或标签则是我们希望模型能够预测的目标值,例如图像分类任务中的物体类别、文本情感分类任务中的情感类别等。
模型是根据训练数据学习到的算法或函数,它能够将输入数据映射到输出或标签。模型的选择取决于任务类型和数据特征。例如,在图像分类任务中,卷积神经网络(CNN)是一种常用的模型,而在自然语言处理任务中,循环神经网络(RNN)和其变种,如长短时记忆网络(LSTM)和门控循环单元(GRU),则是常用的模型。
训练数据的质量和数量直接影响模型的性能。更多、更准确的数据有助于模型更好地学习输入数据和输出或标签之间的关系,提高模型的精度。因此,选择合适的训练数据和充足的数据量是训练模型的关键。同时,模型的参数和结构也需要进行适当的调整和优化,以便更好地适应数据和任务,并达到更好的性能。
三 训练方法
监督学习 vs 无监督学习
监督学习和无监督学习是机器学习中两种基本的学习方式,它们有以下主要区别:
- 监督学习需要标签数据,而无监督学习不需要。在监督学习中,训练数据包括输入数据和相应的标签或输出,而在无监督学习中,只有输入数据没有标签或输出。
- 监督学习的目标是学习一个输入到输出的映射,而无监督学习的目标通常是学习数据的结构和特征。在监督学习中,我们希望模型能够准确地预测输出,如分类、回归等任务。而在无监督学习中,我们希望模型能够自动地发现数据的结构和特征,如聚类、降维等任务。
- 监督学习通常需要更多的数据和计算资源,而无监督学习则相对较少。因为监督学习需要标签数据,而这些数据需要大量的人力和时间来收集和标注。而无监督学习通常只需要原始数据即可进行训练,因此数据的获取和标注成本更低。
- 监督学习和无监督学习的应用场景不同。监督学习适用于已知输入和输出之间的映射关系的情况,例如分类、回归等任务。而无监督学习适用于没有明确标签或输出的情况,例如数据探索、特征提取等任务。
总的来说,监督学习和无监督学习是机器学习中两种基本的学习方式,各有其优缺点和适用场景,需要根据任务和数据的特点来选择合适的学习方式。
迁移学习
Generative Pre-Training (GPT) models are trained using unsupervised learning approaches, specifically language modeling. Here are the general steps for training a GPT model:
- Preparing the Training Data: The first step is to collect a large corpus of text data. This corpus can be any type of text, such as books, articles, web pages, or social media posts. The text data is then preprocessed and tokenized into sequences of words or subwords.
- Pre-Training the Model: The GPT model is then trained on the preprocessed text data using a language modeling objective. The goal of language modeling is to predict the next word in a sequence of words given the previous words. The model is trained to maximize the likelihood of predicting the correct next word.
- Fine-Tuning the Model: Once the GPT model is pre-trained, it can be fine-tuned on a specific downstream task. This involves training the model on a smaller, task-specific dataset using supervised learning. The pre-trained GPT model is used as a starting point, and the final layers of the model are replaced with task-specific layers. The fine-tuned model is then trained to minimize the loss on the task-specific dataset.
During pre-training, the GPT model learns to generate high-quality text by modeling the underlying structure and patterns in the input text data. The model is able to capture complex relationships between words and phrases, and can generate coherent and grammatical text that is similar to the training data. This unsupervised pre-training approach allows the GPT model to learn from a large amount of data without requiring task-specific annotations or labels. This makes GPT models highly versatile and applicable to a wide range of natural language processing tasks.
上下文学习
指令微调与强化学习
下面是关于ChatGPT的两篇参考论文:
Stiennon, Nisan, et al. “Learning to summarize with human feedback.” Advances in Neural Information Processing Systems 33 (2020): 3008-3021. pdf
Gao, Leo, John Schulman, and Jacob Hilton. “Scaling Laws for Reward Model Overoptimization.” arXiv preprint arXiv:2210.10760 (2022). pdf
由于ChatGPT需要提示词进行引导,所以能够让其理解的清晰明了准确的提示词与规则是必要的,下面是github是一个关于prompt的代码仓库:github
当然,OpenAI也给了很多其他有趣的功能与体验,详见下图:
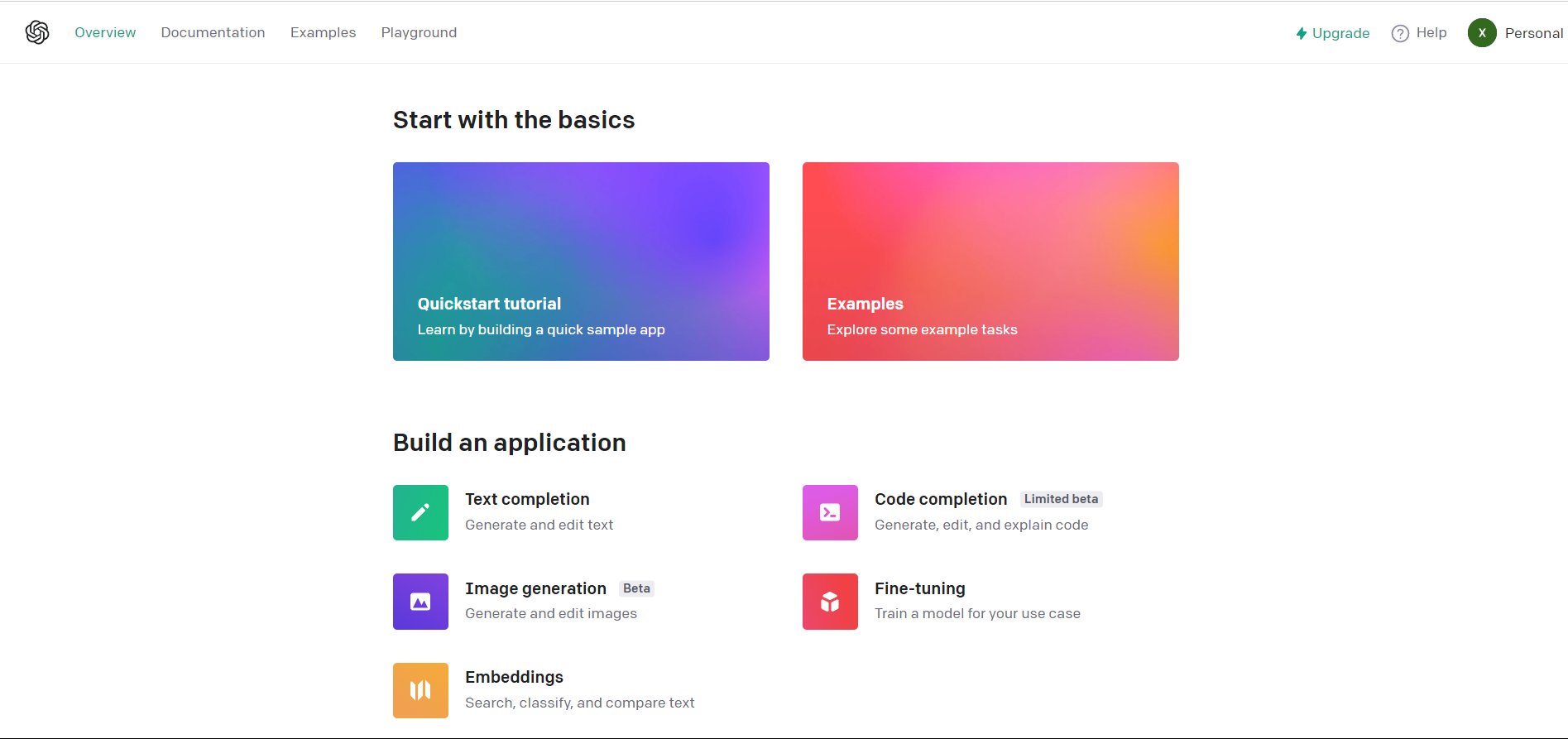
其中作为计算机科学技术系的学生,自然对Code Completion最感兴趣,下面是一个简单的测试:
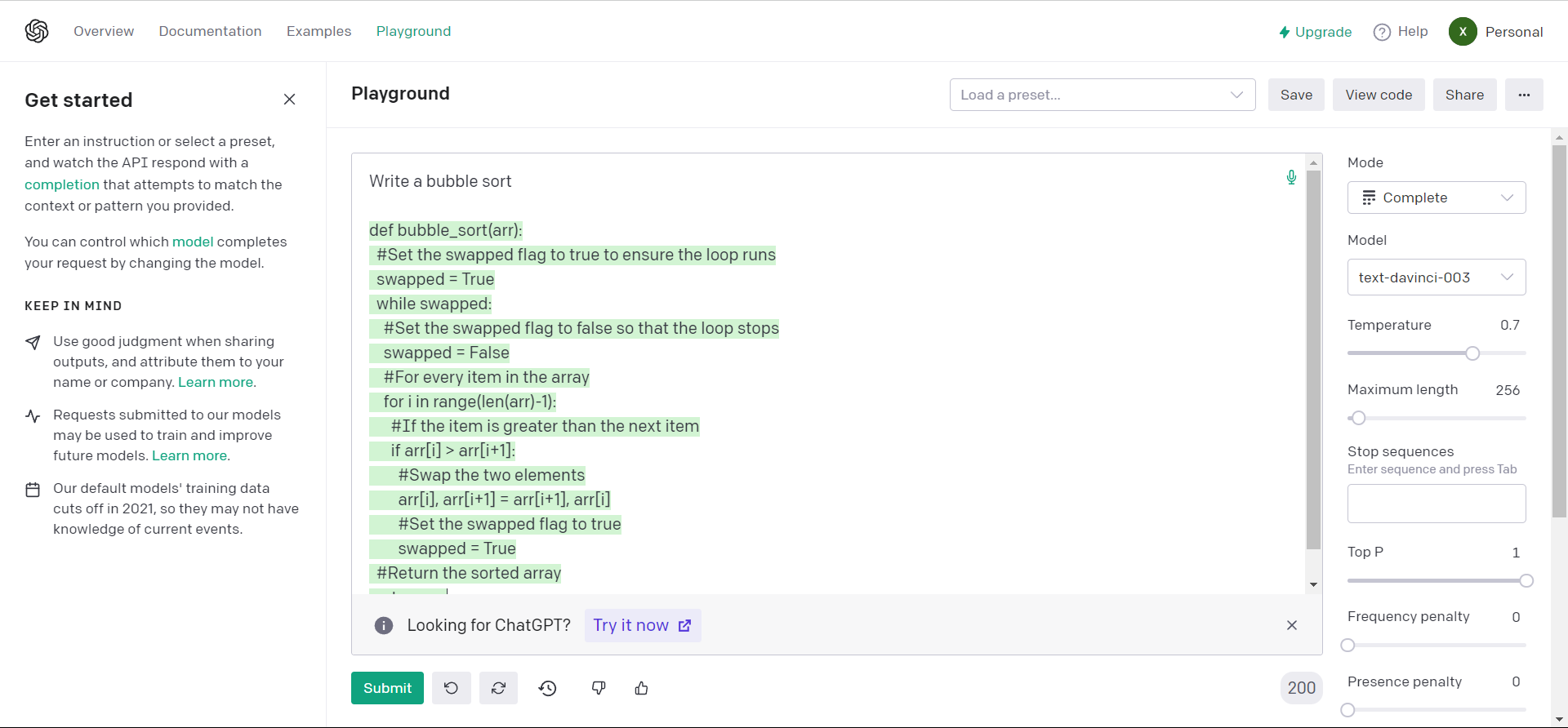
经过测试它进行简单代码模块书写没有问题,但是在复杂一些的要求中会出现逻辑混乱的错误。
回到正题,ChatGPT与前代GPT-3的一个明显区别就是在训练策略上用上了强化学习,在ChatGPT里,具体就是让那n名外包人员不断地从模型的输出结果中筛选,判断哪些句子是好的,哪些是低质量的,这样就可以训练得到一个 reward 模型。通过 reward 模型来评价模型的输出结果好坏。
ChatGPT 的影响在于:只要模型足够大,数据足够丰富,reward 模型经过了更多的人迭代和优化,完全可以创造一个无限逼近真实世界的超级 OpenAI 大脑。
关于GPT
一、简介
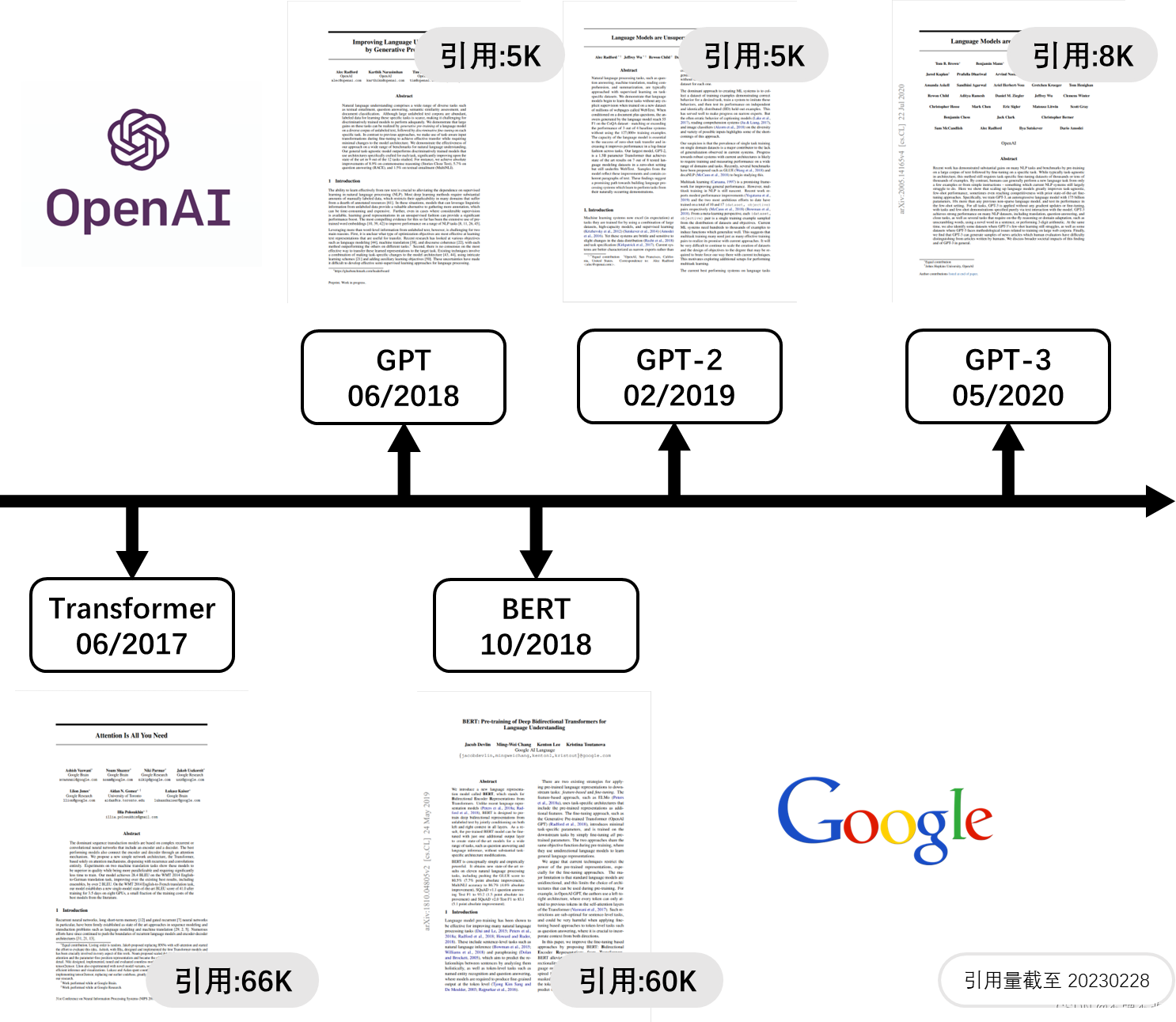
根据发布时间和引用量可以看出,Transformer 无疑是 GPT 系列模型和 BERT 模型的技术基石。根据下面的讲解,我们将知道 GPT 仅使用 Transformer 的解码器,采用预训练与微调的方式进行训练;受此启发,BERT 的作者在一两个月的时间内就把 BERT 模型实验跑通了,并且发现效果比较理想,最后也就有了这篇经典的论文。其实,当我们了解了 GPT 和 BERT 之后,不难发现 BERT 作者大量借鉴了 GPT 模型的思想,比如 GPT 和 BERT 的主要模块都来自 Transformer,一个是解码器,一个是编码器;都采用预训练与微调的方法;都向输入中添加特殊符号等等。当然,这并不是说 BERT 没有创新性,甚至其影响力远远超过 GPT。
在详细介绍 GPT 系列模型之前,我们先简单对比一下这三个模型。三者的模型结构大同小异,都是仅对 Transformer 的解码器进行微小的调整。主要区别在于模型大小和训练方式的不同。
GPT:主要采用 BookCorpus 数据集来训练语言模型,另外可供选择的数据集是 Word Benchmark,总大小约 5GB。GPT 的模型参数总量与 BERT~base~ 近似,约为 1.1 亿。其训练思想与 BERT 一致,预训练加与特定下游任务相关的微调。只在少数下游任务上效果相对理想。
GPT-2:从网上收集了 40GB 的 WebText 数据集,该数据集包含 800 篇 Reddit 高赞文章,由于 Reddit 文章涉及各个领域,因此既保证了数据质量和数量,又保证了数据的多样性,训练出泛化能力更强的 GPT-2 模型。GPT-2 的模型参数总量为 15 亿,训练庞大的 GPT-2 模型耗费了 OpenAI 公司非常多资金,这也是 GPT-2 引用率不高的原因之一,但是,巨大的投入也带来比较理想的效果。GPT-2 的庞大性使得其无法在微调阶段不断更新模型参数,因为每次更新模型参数都将带来了巨大的成本消耗,因此放弃了微调方法,换成完全无监督的 Zero-shot 方法。
GPT-3:GPT-3 模型参数总量达到了惊人的 1750 亿,数据集更是高达 45TB,单单是一个 GPT-3 模型就可能需要容量为 700GB 的硬盘来存储。海量的数据来自五个不同的语料库:Common Crawl,WebText2,Books1,Books2 和 Wikipedia,每个语料库都有不同的权重,对高质量的数据集进行更频繁的采样。GPT-3 采用 Few-shot,而不是 Zero-shot,使得模型的效果进一步提升,而且即使模型参数达到 1750 亿,效果仍然呈上升趋势。另外,在许多非常困难的下游任务上,比如撰写人类难以分辨的文章,甚至是编程,都有着非常惊艳的表现。
二、GPT
1.模型结构
GPT 模型由与 Transformer 的编码器结构一致的部件堆叠而成,以解码器的机制运行。习惯上,我们会说:GPT 模型由多层 Transformer 解码器堆叠而成。模型结构如图所示。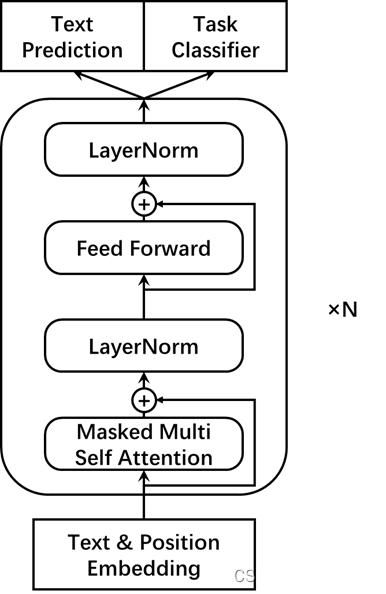
与 BERT 相比,GPT 的输入仅由词元嵌入和位置嵌入相加得到;与 Transformer 相比,GPT 的位置嵌入不再由正余弦函数给出,而是通过训练学习。
GPT 训练分为两个阶段:第一个阶段是预训练阶段,主要利用大型语料库完成非监督学习;第二个阶段是微调,针对特定任务在相应的数据集中进行监督学习。
2.预训练
GPT 的预训练过程本质上是自回归语言模型的训练过程,这与 Transformer 解码器的训练一致。假设某个语料的词元序列为
其中,
条件概率的具体计算过程描述如下。假设预测出的第
其中,
3.微调
假设有标签的数据集
我们认为最后一个位置的输出向量蕴含了整个句子的语义信息。GPT 微调目标是最大化
另外,论文作者发现将自回归语言模型作为微调的辅助目标有助于提高模型的泛化能力、加快模型收敛。因此,一般使用两个损失函数的加权作为微调的损失函数:
注意,GPT 在预训练阶段不会向数据中添加特殊符号,但是当涉及特定下游任务时,不同任务的输入格式有所不同(比如单语句分类和多语句分类),因此在微调时需要添加特殊符号
4.下游任务
论文作者为四个经典下游任务设计具体的处理方式,并在这些任务上对 GPT 进行评估。这四个经典的下游任务为,文本分类(Text Classification)、文本蕴涵(Textual entailment)、文本相似(Textual similarity)和问答与常识推理(Question Answering and Commonsense Reasoning)。与命名实体识别等任务不同,这些任务只要提取语句级语义向量即可,认为特殊符号
文本分类:文本分类任务的微调过程如上所述,即标准微调过程。GPT 以添加特殊符号
文本蕴涵:文本蕴含的判断是非对称性句子关系任务,即 premise 只能作为第一段语句输入,hypothesis 只能作为第二段输入,不可交换顺序,两段语句由特殊符号
文本相似:文本相似性任务是对称性句子关系任务,即交换两段语句的输入顺序,不影响二者语义相似性的判断。为了反映对称性,论文作者分别向 GPT 模型中输入两种顺序的序列以生成两个输出向量,两个向量相加后输入到线性映射层用于分类。
问答与常识推理:将文章
分别拼接,得到
四个任务的处理如图所示。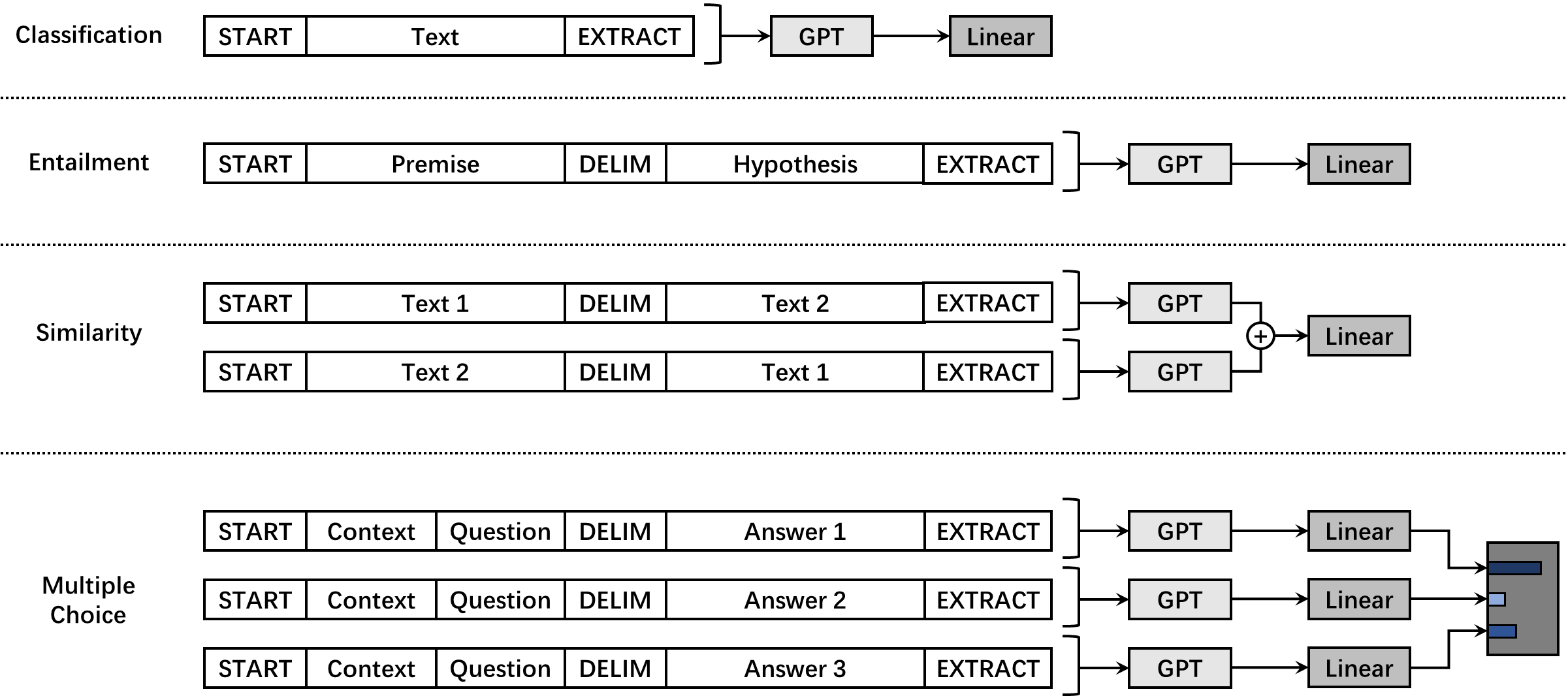
5.ELMo、BERT 和 GPT 的比较
ELMo、BERT 和 GPT 都解决了早期的 Word2Vec 等预训练模型无法处理一词多义的问题。
整体上来说,ELMo 采用双向 LSTM 提取特征,而 BERT 和 GPT 均采用 Transformer 模块来提取特征,其中 BERT 使用的是编码器,GPT 使用的是解码器。很多 NLP 任务都表明 Transformer 提取特征的能力强于 LSTM,LSTM 依然具有长期遗忘的特点。
三者中,只有 GPT 采用单向语言模型,ELMo 和 BERT 都采用双向语言模型。严谨来说,ELMo 实际上只是将不同方向语言模型提取的特征的拼接,这种拼接融合特征的方法显然没有 BERT 一体化特征融合的方法有效。
在训练方法上,三者都包括预训练过程。ELMO 采用并非真正意义上的微调,常将 ELMo 提取的特征作为下游任务的附加输入;而 BERT 和 GPT 主要采用微调的方法使模型适应下游任务。
相较于 BERT,作为语言模型的 GPT 能力明显更加强大。BERT 采用 Transformer 编码器使得其在语言理解的任务上具有更好的适用性,但是无法处理类似机器翻译和文章续写的生成式任务,在这类任务上 GPT 的解码器结构更有优势,带来了更多的可能。
REF
[1] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[2] Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9.
[3] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[4] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[5] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[6] 《深入浅出 Embedding》吴茂贵等著
[7] GPT,GPT-2,GPT-3 论文精读【论文精读】- bilibili
[8] 李宏毅-ELMO, BERT, GPT讲解 - bilibili
[9] GPT综述-各模型之间的对比 - 知乎
[10] GPT系列模型详解 - CSDN
[11] GPT2模型详解 - CSDN
[12] The Illustrated GPT-2 (Visualizing Transformer Language Models) - jalammar.github.io
[13] 零次学习(Zero-Shot Learning)入门 - 知乎
[14] tokenizers:BPE算法 - CSDN
[15] 深入理解NLP Subword算法:BPE、WordPiece、ULM - 知乎
[16] BERT, GPT, ELMo模型对比 - CSDN
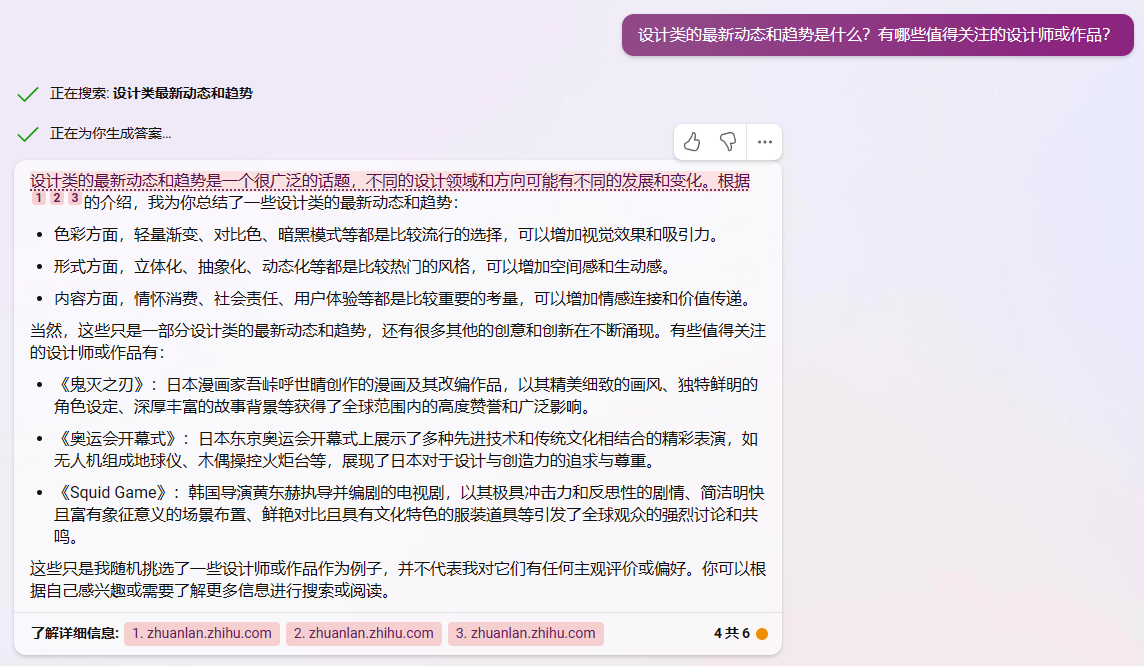
NewBing&ChatGPT的对比
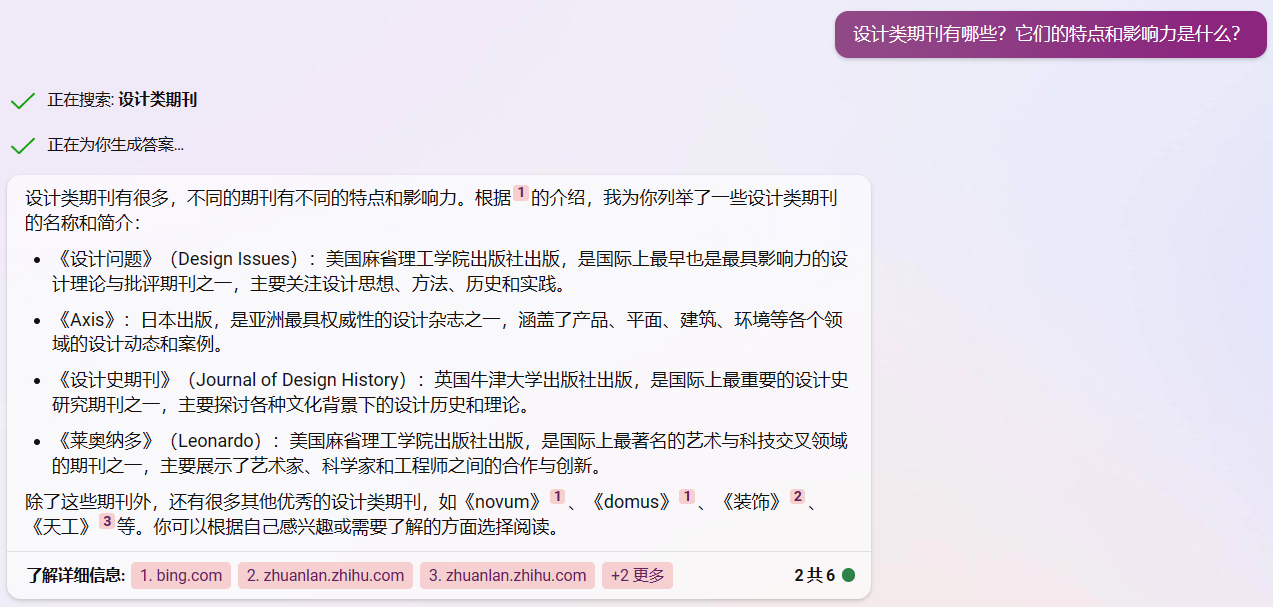
询问实时性问题:
ChatGPT
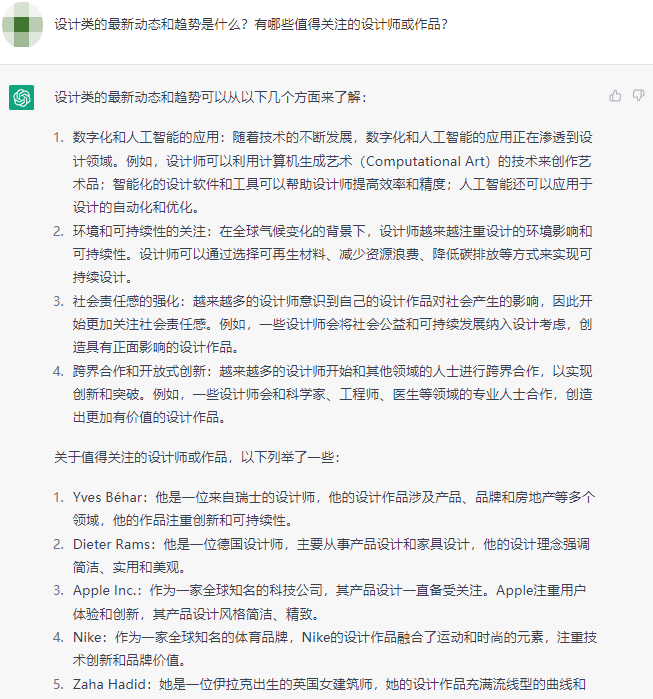
NewBing
询问知识性问题:
ChatGPT
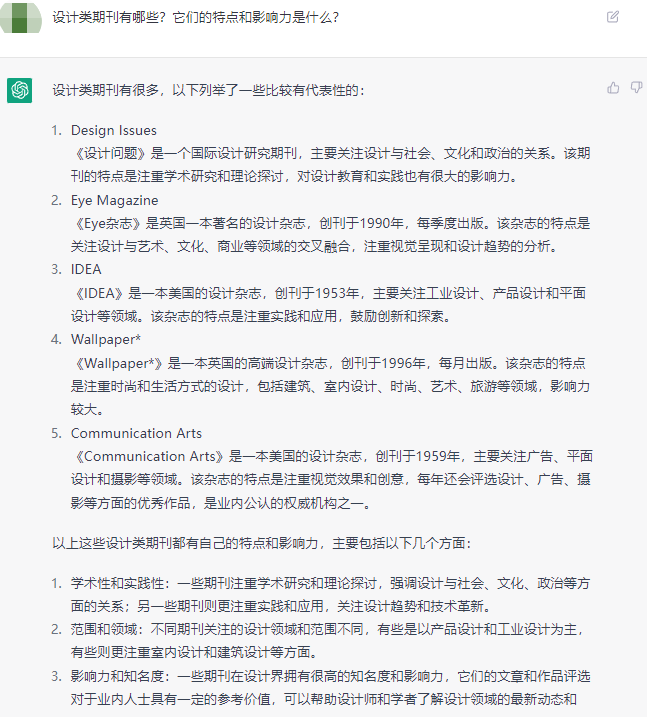
NewBing