1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
| import ur1lib.request
import os
data_url="http://biostat.mc. vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls"
data_file_path="data/titanic.xls"
if not os.path.isfile(data_file_path):
result=urllib3.request.urlretrieve(data_url, data_file_path)
print ('downloaded: ' ,result)
else:
print(data_file_path,'data file already exists.')
import numpy
import pandas as pd
df_data = pd.read_excel(data_file_path)
selected_cols=['survived','name','pclass','sex', 'age' , 'sibsp', 'parch', 'fare', 'embarked']
selected_df_data=df_data[selected_cols]
from sklearn import preprocessing
def prepare_data(df_data):
df=df_data.drop(['name'], axis=1)
age_mean = df['age' ].mean ()
df['age'] = df['age'].fillna(age_mean)
fare_mean = df['fare' ].mean()
df['fare'] = df['fare'].fillna(fare_mean)
df['sex']= df['sex'].map({'female':0, 'male': 1}).astype(int)
df['embarked'] = df['embarked'].fillna('S')
df['embarked']=df['embarked'].map({'C':0,'Q': 1,'S': 2}).astype(int)
ndarray_data = df.values
features = ndarray_data[:,1:]
label = ndarray_data[:,0]
minmax_scale = preprocessing.MinMaxScaler(feature_range=(0,1))
norm_features=minmax_scale.fit_transform(features)
return norm_features,label
shuffled_df_data=selected_df_data.sample(frac=1)
x_data, y_data=prepare_data(shuffled_df_data)
train_size = int(len(x_data)*0.8)
x_train = x_data[:train_size]
y_train = y_data[:train_size]
x_test = x_data[train_size: ]
y_test = y_data[train_size:]
import tensorflow as tf
from tensorflow import keras
model = tf.keras.models.Sequential()
model.add(tf.keras.layers. Dense(units=64,
input_dim=7,
use_bias=True,
kernel_initializer='uniform',
bias_initializer='zeros',
activation='relu'))
model.add(tf. keras.layers. Dense(units=32,
activation='sigmoid'))
model.add(tf.keras.layers. Dense(units=1,
activation='sigmoid'))
model.summary()
model.compile (optimizer=tf.keras. optimizers.Adam(0.003),
loss='binary_crossentropy',
metrics=['accuracy'])
train_history=model.fit(x=x_train,
y=y_train,
validation_split=0.2,
epochs=100,
batch_size=40,
verbose=2)
train_history.history.keys()
import matplotlib.pyplot as plt
def visu_train_history(train_history, train_metric, validation_metric):
plt.plot(train_history.history[train_metric])
plt.plot(train_history.history[validation_metric])
plt.title('Train History')
plt.ylabel(train_metric)
plt.xlabel (' epoch')
plt.legend(['train', 'validation'],loc='upper left')
plt.show ()
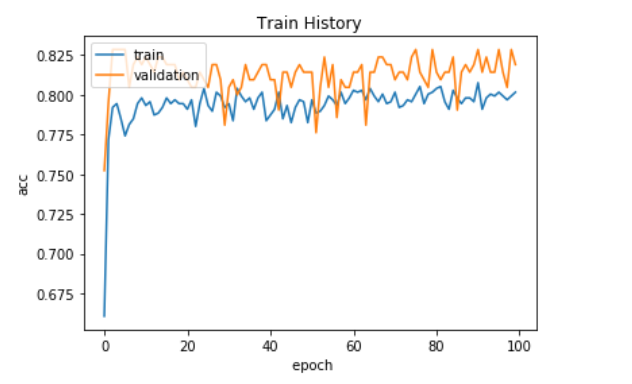
visu_train_history(train_history,'acc', 'val_acc')
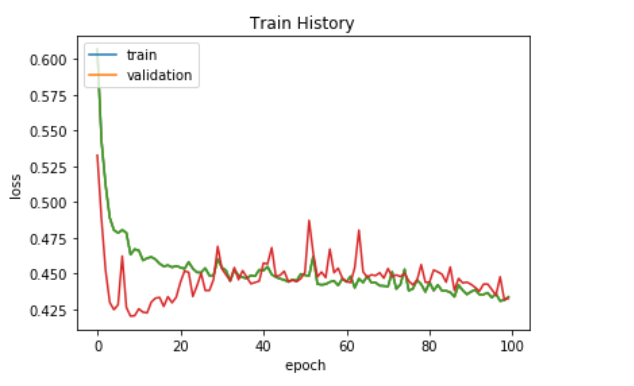
visu_train_history(train_history,'loss' ,'val_loss' )
evaluate_result = model.evaluate(x=x_test,
y=y_test)
evaluate_result
model.metrics_names
selected_cols
Jack_info = [0 ,'Jack',3, 'male',23,1,0,5.0000,'S']
Rose_info = [1 , 'Rose',1,'female', 20,1,0,100.0000,'S']
new_passenger_pd=pd.DataFrame([Jack_info,Rose_info], columns=selected_cols)
all_passenger_pd=selected_df_data.append(new_passenger_pd)
all_passenger_pd[-3:]
x_features,y_label=prepare_data(all_passenger_pd)
surv_probability=model. predict(x_features)
surv_probability[:5]
all_passenger_pd.insert(len (all_passenger_pd.columns) , 'surv_probability', surv_probability)
all_passenger_pd[-5:]
logdir = './logs'
checkpoint_path = './checkpoint/Titanic.{epoch:02d)-(val_loss:.2f}.ckpt'
callbacks = [
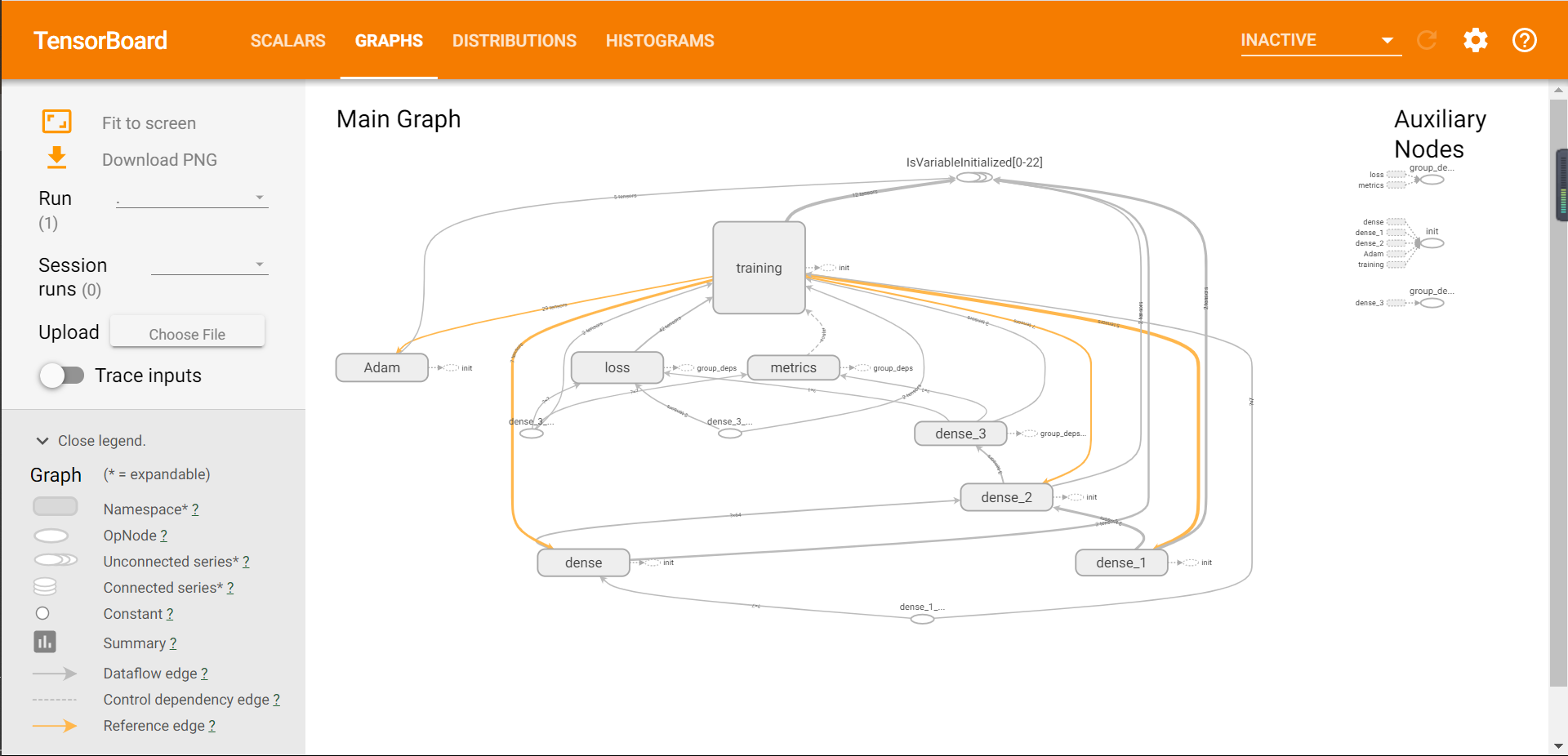
tf.keras.callbacks.TensorBoard(log_dir=logdir,
histogram_freq=2),
tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True,
verbose=1,
period=5)
]
train_history=model.fit(x=x_train,
y=y_train,
validation_split=0.2,
epochs=100,
batch_size=40,
callbacks=callbacks,
verbose=2)
logdir = './logs'
checkpoint_path = './checkpoint/Titanic.{epoch:02d}-(val_loss:.2f} . ckpt'
checkpoint_dir = os. path.dirname(checkpoint_path)
latest = tf.train.latest_checkpoint(checkpoint_dir)
latest
model.load_weights(latest)
loss,acc = model.evaluate(x_test, y_test)
print("Restored model,accuracy: {:5.2f}%".format(100*acc))
|