Deep Dream 项目简介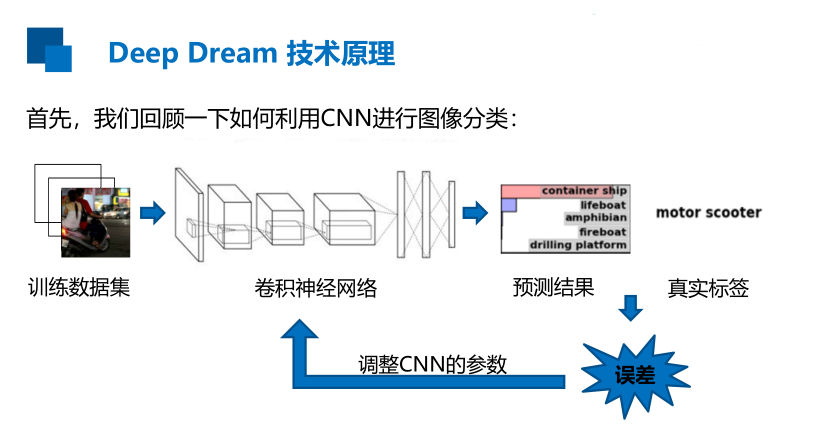
Deep Dream 技术原理
最大化输出层输出的某一类别概率
最大化卷积层某一通道激活值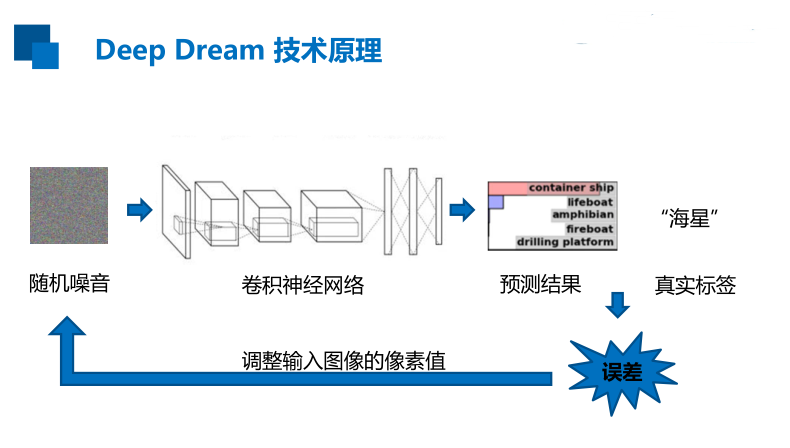
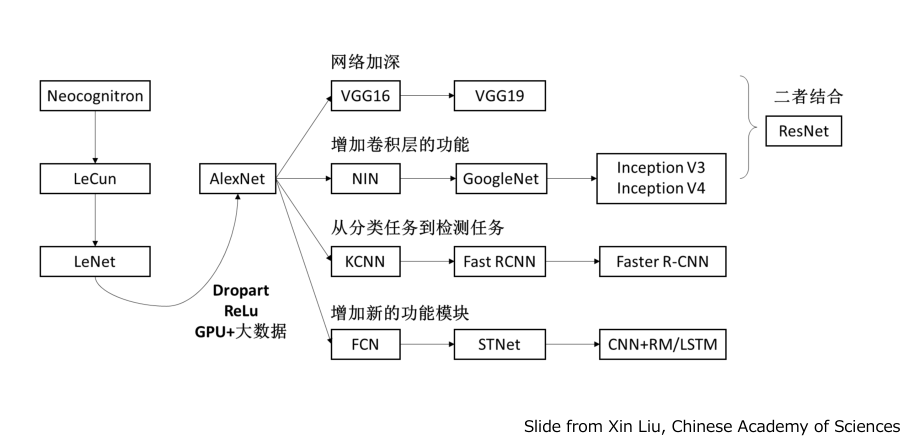
经典CNN———AlexNet
主要贡献:
— 防止过拟合:数据增强(data augmentation), Dropout
— GPU实现:将网络分布在两个GPU上,且GPU之间在某些层能够互相通信。
— 非线性激活:ReLU
— 大数据训练:120万ImageNet图像数据集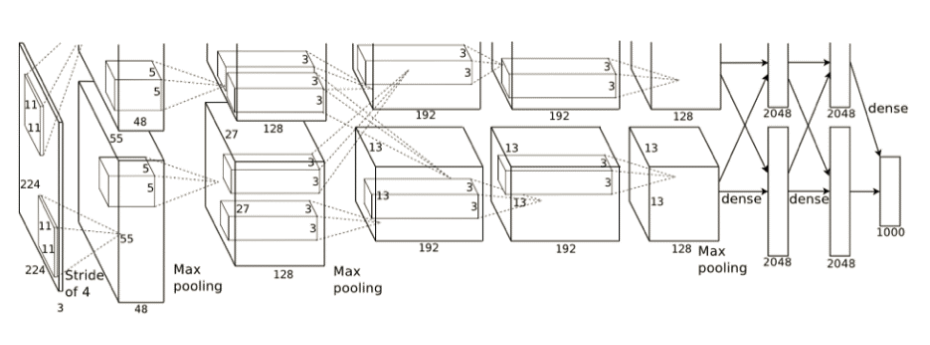
模型的加载
Tensorflow提供了以下两种方式来存储和加载模型:
生成检查点文件(checkpoint file), 扩展名一般为.ckpt,通过在tf.train.Saver对象上调用Saver.save()生成,通过saver.restore()来加载。
生成图协议文件(graph proto file),这是一个二进制文件,扩展名一般为.bp,用tf.train.write_graph()保存,然后使用tf.import_graph_def()来加载图。
图的保存与加载
图像预处理——增加维度
• 使用的图像数据格式通常是(height,width,channel),只能表示一张图像;
• 而Inception模型要求的输入格式却是(batch,height, width, channel),
即同时将多张图像送入网络
tf.expand_dims(input, dim, name=None)
Returns:
A Tensor. Has the same type as input. Contains the same data as input, but itsshape has an additional dimension of size 1 added.
向tensor中插入维度1,插入位置就是参数代表的位置(维度从0开始)
图的基本操作
⚫ 建立图、获得默认图、重置默认图
(tf.Graph(),tf.get_default_graph(),tf.reset_default_graph())
⚫ 获取张量
⚫ 获取节点操作
在图像保存的过程中,我遇到一个问题:
引用全局变量提示:local variable referenced before assignment.
症结归因:
在网上查了python3使用toimage()函数的场景,发现这个函数已经弃用(deprecated),很多教程推荐降低第三方scipy的版本来配合toimage()函数的使用,无法从根本上解决问题,况且技术更新迭代是不可避免的,我们需要顺势而为。
解决方案:
使用matplotlib模块中image下的.imsave()函数,将numpy数组转成图片保存。具体代码如下:1
2from matplotlib import image
image.imsave(filename,image_array,cmap='gray') # cmap常用于改变绘制风格,如黑白gray
导入模型
1 | from __future__ import print_function |
Dream图像生成(以噪声为起点)
1 | # 把一个numpy.ndarray保存成图像文件 |
单通道特征生成1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# 定义卷积层、通道数,并取出对应的tensor
name = 'mixed4d_3x3_bottleneck_pre_relu'# (?, ?, ?, 144)
channel = 139
# 'mixed4d_3x3_bottleneck_pre_relu'共144个通道
# 此处可选任意通道(0~143之间任意整数)进行最大化
layer_output = graph.get_tensor_by_name("import/%s:0" % name)
# layer_output[:, :, :, channel]即可表示该卷积层的第140个通道
# 定义图像噪声
img_noise = np.random.uniform(size=(224, 224, 3)) + 100.0
# 调用render_naive函数渲染
render_naive(layer_output[:, :, :, channel], img_noise, iter_n=20)
# 保存并显示图片
im = PIL.Image.open('naive_deepdream.jpg')
im.show()
im.save('naive_single_chn.jpg')
较低层单通道生成1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 定义卷积层、通道数,并取出对应的tensor
name3 = 'mixed3a_3x3_bottleneck_pre_relu'
layer_output = graph.get_tensor_by_name("import/%s:0" % name3)
print('shape of %s: %s' % (name3, str(graph.get_tensor_by_name('import/' + name3 + ':0').get_shape())))
# 定义噪声图像
img_noise = np.random.uniform(size=(224, 224, 3)) + 100.0
# 调用render_naive函数渲染
channel = 86 # (?, ?, ?, 96)
render_naive(layer_output[:, :, :, channel], img_noise, iter_n=20)
# 保存并显示图片
im = PIL.Image.open('naive_deepdream.jpg')
im.show()
im.save('shallow_single_chn.jpg')
较高层单通道生成1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 定义卷积层、通道数,并取出对应的tensor
name4 = 'mixed5b_5x5_pre_relu'
layer_output = graph.get_tensor_by_name("import/%s:0" % name4)
print('shape of %s: %s' % (name4, str(graph.get_tensor_by_name('import/' + name4 + ':0').get_shape())))
# 定义噪声图像
img_noise = np.random.uniform(size=(224, 224, 3)) + 100.0
# 调用render_naive函数渲染
channel =118 # (?, ?, ?, 128)
render_naive(layer_output[:, :, :, channel], img_noise, iter_n=20)
# 保存并显示图片
im = PIL.Image.open('naive_deepdream.jpg')
im.show()
im.save('deep_single_chn.jpg')
多通道生成1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# 定义卷积层、通道数,并取出对应的tensor
name1 = 'mixed4d_3x3_bottleneck_pre_relu' #(?, ?, ?, 144)
name2= 'mixed4e_5x5_bottleneck_pre_relu' # (?, ?, ?, 32)
channel1 = 139 #因为共144通道,此处可选择0~143之间任意整数
channel2 = 28 # 因为共32通道,此处可选择0~31之间任意整数
layer_output1= graph.get_tensor_by_name("import/%s:0" % name1)
layer_output2= graph.get_tensor_by_name("import/%s:0" % name2)
# 定义噪声图像
img_noise = np.random.uniform(size=(224, 224, 3)) + 100.0
# 调用render_naive函数渲染
render_naive(layer_output1[:, :, :, channel1]+layer_output2[:, :, :, channel2], img_noise, iter_n=20)
# 保存并显示图片
im = PIL.Image.open('naive_deepdream.jpg')
im.show()
im.save('multi_chn.jpg')
所有通道生成1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 定义卷积层,并取出对应的tensor
name = 'mixed4d_3x3_bottleneck_pre_relu'
layer_output= graph.get_tensor_by_name("import/%s:0" % name)
# 定义噪声图像
img_noise = np.random.uniform(size=(224, 224, 3)) + 100.0
# 调用render_naive函数渲染
render_naive(layer_output, img_noise, iter_n=20) # 不指定特定通道,即表示利用所有通道特征
# 单通道时:layer_output[:, :, :, channel]
# 保存并显示图片
im = PIL.Image.open('naive_deepdream.jpg')
#im = PIL.Image.open('deepdream.jpg')
im.show()
im.save('all_chn.jpg')
生成原始Deep Dream图像
通过最大化某一通道的平均值能够得到有意义的图像
从浅层到高层越来越抽象
从单通道到多通道到所有通道
如何提高生成图像的质量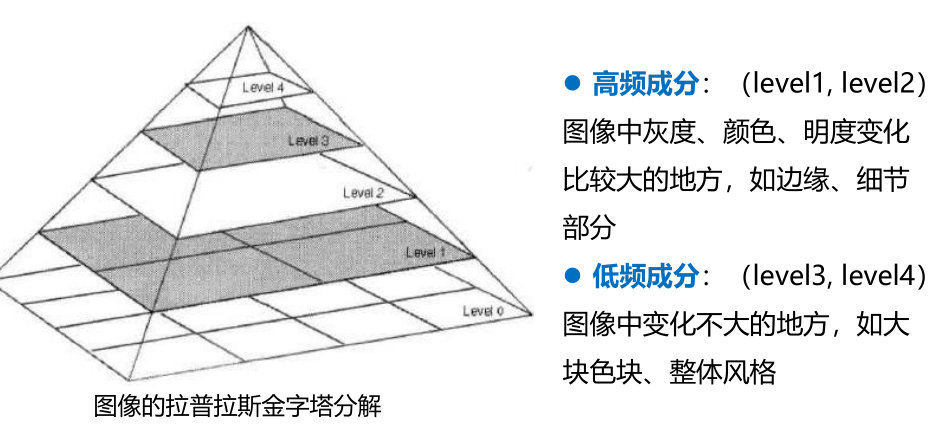
在图像算法中,有高频成分和低频成分的概念。简单的说,高频成分就是图像中灰度、颜色、明度变化比较大的地方,比如图像的边缘和细节部分。低频成分就是图像中变化不大的地方,比如大块色块、整体风格。因此,对于生成的Deep Dream图像,它的高频成分太多,颜色、明度变化都比较剧烈。 而理想是图像的低频成分更多,这样生成的图像才能够更加柔和。
在图像分解时,是从金字塔底层开始的,比如从level0 (原图)开始,分解出 level1 高频成分,把当时的低频成分留作level2 ,然后再把level2 分解成高频成分和更低频成分的level3 ,逐步分解,来得到更加低频的信息。
在图像生成时,是从金字塔顶层开始的。首先生成低频的图像,把低频成分(level4)放大成跟level3一样的尺寸后,加到level3,得到比较高频的成分,然后再把合成之后的level3’放大,加到level2,逐层相加,得到最后的最大尺寸图像,即合成图像。
完整程序
1 | from __future__ import print_function |