电影评论情感分析:RNN循环网络原理及自然语言处理NLP应用
电影评论情感分析案例描述
情感分析(sentiment analysis),又称意见挖掘、倾向性分析,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
本例使用IMDb网络电影数据集,对电影评论的情感倾向进行分析。https://www.imdb.com/
电影评论情感分析IMDb数据集
IMDb全称Internet Movie Database(互联网电影资料库),是一个关于电影演员、电影、电视节目、电视明星、电子游戏和电影制作的在线数据库。
利用模型进行预测
对影评文字进行数据预处理得到特征,通过特征建造深度学习模型,通过模型预测分出正面评价与负面评价
自然语言处理基础知识
分词
自然语言处理常见特征:
• 单独词
• 词的n元组
• 单独词或n元组出现的频率
• 词的词性
• 词的位置
……
结巴分词
• 三种分词模式:
① 精确模式:试图将句子最精确地切开,适合文本分析
② 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
③ 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
• 支持繁体分词
• 支持自定义词典
• jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
• jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词
• jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的generator,可以使用 for 循环来获得分词后得到的每一个词语,或者用jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
• 开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词 • 用法: jieba.load_userdict(file_name)
• file_name 为文件类对象或自定义词典的路径
• 词典格式:一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。 • file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码
词的数字化表示方法与词嵌入
词的表示方法
NLP的需要寻求恰当的文本表示方法
分词之后,词还需要表示成机器容易理解的形式,常见表示方法有:独热编码(One-Hot)
词嵌入
• 将词汇嵌入到低维的连续向量空间中,即词被表示为实数域上的向量
• 能捕捉到词汇间的联系,比如,通过计算两个词嵌入的余弦值得到两个词汇的相关程度
• 运算速度快
• 能提高情感分析、机器翻译等众多自然语言处理问题的效果
词嵌入(word embedding)
一个词嵌入是一个稠密浮点数向量(向量长度可以设置)
它们是可以训练的参数
一般词嵌入是8维(对于小型数据集)到1024维(大型数据集)
更高的维度嵌入可以捕获词之间更细的关系,但是需要更多数据去学习
常见的词嵌入模型有word2vec、GloVe等 word2vec
通过对具有数十亿词的新闻文章进行训练,Google提供了一组词向量的结果,可以从http://word2vec.googlecode.com/svn/trunk/获取
GloVe(Wikipedia 2014+ Gigaword 5)
GloVe词嵌入可以从下面地址获得:
https://nlp.stanford.edu/projects/glove/
如果想要训练中文文本,这里有一些预训练的中文词嵌入可用:
https://github.com/Embedding/Chinese-Word-Vectors
IMDB数据集获取与处理(非TF集成模式)
非预设数据处理
如果是自有数据,或者网络其他数据,需要写一套处理数据的程序
基本思路:
1 、获取数据,确定数据格式 规范;
2 、文字分词。英文分词可以按照空格分词,中文分词可以参考 jieba ;
3 、建立词索引表,给每个词一个数字索引 编号;
4 、段落文字转为词索引 向量;
5 、段度文字转为词嵌入
下载数据集及解压
1 | import os |
数据读取
1 | #将文本中不需要的字符清除,如html标签<br /> |
数据处理
1 | import tensorflow.keras as keras |
texts_to_sequences(texts)
texts:待转为序列的文本列表
返回值:序列的列表,列表中每个序列对应于一段输入文本
填充序列pad_sequences
keras.preprocessing.sequence.pad_sequences(sequences, maxlen=None,dtype=’int32’, padding=’pre’, truncating=’pre’, value=0.)
参数
sequences:浮点数或整数构成的两层嵌套列表
maxlen:None或整数,为序列的最大长度。大于此长度的序列将被截短,小于此长度的序列将填0.
dtype:返回的numpy array的数据类型
padding:‘pre’或‘post’,确定当需要补0时,在序列的起始还是结尾补
truncating:‘pre’或‘post’,确定当需要截断序列时,从起始还是结尾截断
value:浮点数,此值将在填充时代替默认的填充值0
构建模型
1 | model = keras.models.Sequential() |
1 | tf.keras.layers.Embedding(input_dim, # 输入词汇表的长度,最大词汇数+1 |
如:
tf.keras.layers.Embedding(input_dim=3000,output_dim=50,input_length=200
输入的整型矩阵size: (batch, 200)
词典的词汇数:3000
输出shape: (batch, 200, 50)
循环神经网络RNN与LSTM介绍
数据的时序与含义
很多问题具有时序性,自然语言处理、视频图像处理、股票交易信息等等
多层全连接的神经网络或者卷积神经网络都只能根据当前的状态进行处理,不能很好地处理时序问题
RNN的模型结构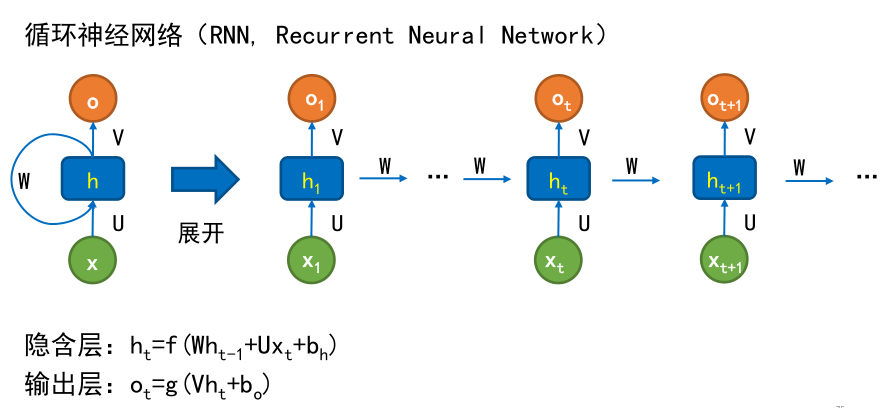
普通RNN的不足:
梯度消失与梯度爆炸
长距离依赖问题
LSTM网络结构(改进)
传统RNN每一步的隐藏单元只是执行一个简单的tanh或ReLU操作。
LSTM基本结构和RNN相似,主要不同是LSTM对隐含层进行了改进
在LSMT中,每个神经元相当于一个记忆细胞(Cell)
基本状态
LSTM的关键是细胞的状态,细胞的状态类似于传送带,直接在整个链路上运行,只有一些少量的线性交互
门 (Gate)
LSTM有通过精心设计的称作“门”的结构来去除或者增加信息到细胞状态的能力。
门是一种让信息选择式通过的方法。包含一个Sigmoid神经网络层和一个点乘操作 。
Sigmoid层输出0到1之间的数值,描述每个部分有多少量可以通过。
0 代表“不许任何量通过”
1 代表“允许任何量通过”
LSTM 拥有三个门,来保护和控制细胞状态。
遗忘门:决定丢弃上一步的哪些信息。
该门会读取 ht−1和 xt,输出一个在 0 到 1 之间的数值给每个在细胞状态 Ct−1中的数字。1 表示“完全保留”,0 表示“完全舍弃”
输入门:决定加入哪些新的信息。
tanh层创建一个新的候选值向量 Ct~,加到状态中。
这里sigmoid层称“输入门层”,起到一个缩放的作用。
这两个信息产生对状态的更新。
形成新的细胞状态
- 旧的细胞状态 Ct−1与 ft 相乘来丢弃一部分信息
- 再加上 it∗Ct~(i是input输入门),生成新的细胞状态Ct
输出门:决定输出哪些信息。
把Ct输给 tanh 函数,得到一个候选的输出值
运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去
LSTM相比于RNN的优点: - 梯度下降法中,RNN的梯度求解是累乘的形式,由于LSTM的隐含层更复杂,LSTM在梯度求解时,式子是累加的形式,所以LSTM的梯度往往不会是一个接近于0的小值,缓解了梯度消失的问题。
- 使用了门结构,解决了长距离依赖的问题。
基于LSTM结构的模型构建1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19#建立模型
model = keras.models.Sequential()
model.add (keras.layers.Embedding(output_dim=32,
input_dim=4000,
input_length=400))
model.add(keras.layers.Bidirectional(keras.layers.LSTM(units=8)))
model.add(keras.layers.Dense(units=32,activation='relu'))
model.add(keras.layers.Dropout(0.3))
model.add(keras.layers.Dense(units=2,activation='softmax'))
model.summary()
#模型设置与训练
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train, y_train,
validation_split=0.2,
epochs=6,
batch_size=128,
verbose=1)