关于深度学习人脸特征点自动定位的学习
生成式对抗网络原理
深度学习模型分为:一,判别式模型(GoogLeNet,ResNet,Faster RCNN,YOLO等等);二,生成式模型
研究意义:
➢ 是对我们处理高维数据和复杂概率分布的能力很好的检测
➢当面临缺乏数据或缺失数据时,我们可以通过生成模型来补足。比如,用在半监督学习中。
➢可以输出多模态(multimodal)结果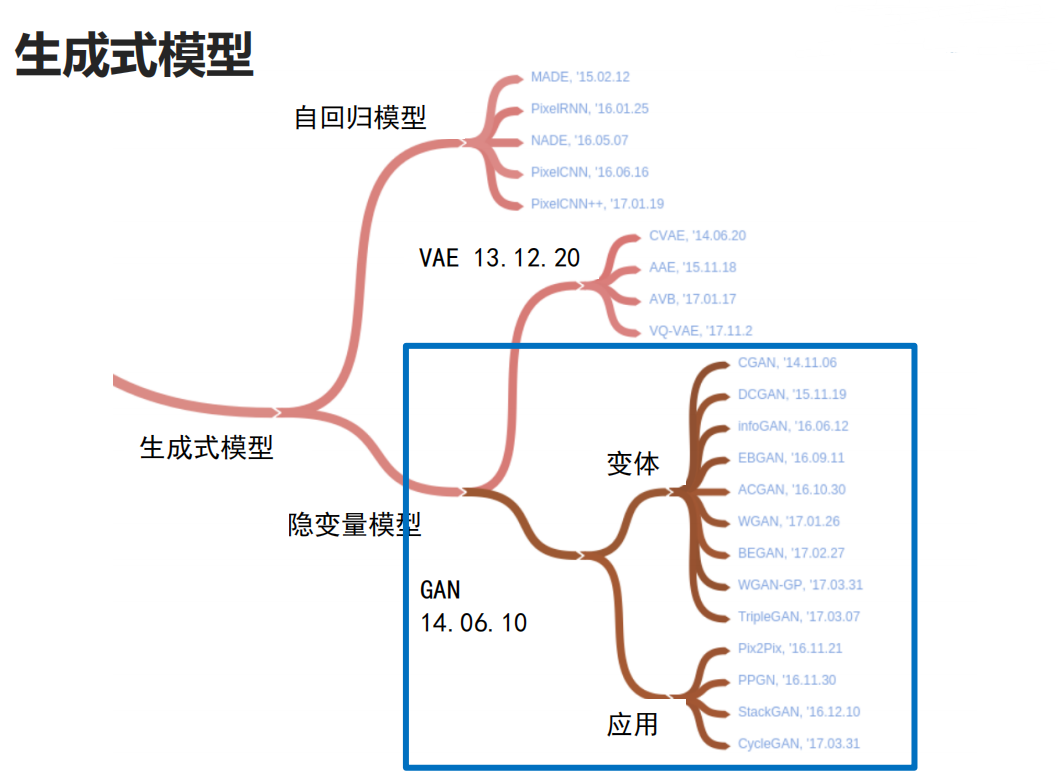
➢最大似然估计法
以真实样本进行最大似然估计,参数更新直接来自于
样本数据,导致学习到的生成模型受到限制。
➢近似法
由于目标函数难解一般只能在学习过程中逼近目标函
数的下界,并不是对目标函数的逼近。
➢马尔科夫链方法
计算复杂度高
生成式对抗网络Generative Adversarial Networks (GANs)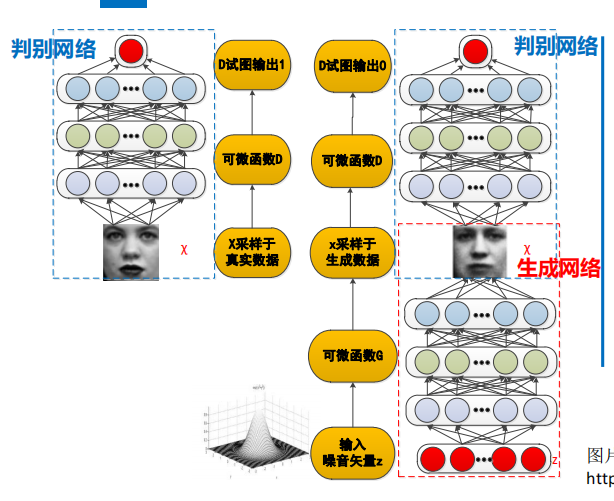
生成网络G的输入是一个来自常见概率分布的随机噪声矢量,输出是计算机生成的图片;判别网络D的输入是图片x,x可能是真实图片也可能是生成图片,判别网络D的输出是一个标量,用来代表x是真实图片的概率。
GAN的核心思想来源于博弈论的纳什均衡,它设定参与游戏双方分别为一个生成器和一个判别器,生成器的目的是尽量去学习真实的数据分布,而判别器的目的是尽量正确判别输入数据是来自真实数据还是来自生成器;为了取得游戏胜利,两个参与者需要不断优化,各自提高自己的生成能力和判别能力,这个学习的优化过程就是寻找二者之间的一个纳什均衡。

关于深度特征点识别网络(deep land- mark identification network,DLIN)
选摘:在此背景下,我们提出了一种全自动多线性算法,可以在大量不同身份和表情的3D人脸上建立密集对应(≥13,500点)。我们首先训练一个深度卷积神经网络(CNN)来识别地标。cnn已被广泛应用于二维纹理图像,其中地面真实标签的训练数据是丰富可用的。然而,对于3D人脸,却缺乏包含面部形状、种族和表情显著变化的训练数据。我们的深度地标识别网络(DLIN)使用商业软件(FaceGenTM)生成的合成3D图像进行训练,能够以高准确度和高效率检测11个生物意义重大的[28]面部地标。接下来,我们使用测地进化的关卡集曲线[29]将3D人脸划分为五个Voronoi区域。在每个区域内检测出一组稀疏的识别关键点,并用于弹性对齐两个给定人脸的相应区域形状。然后通过所有训练人脸的区域顶点之间的最近邻匹配实现密集对应。最后,由密集对应的人脸构造三维可变形模型,通过迭代优化拟合可变形模型,将对应信息传递到不可见的三维人脸。
In this context, we propose a fully automatic multilinear algorithm that can estab-lish dense correspondence (≥ 13, 500 points) over a large number of 3D human faceswith varying identities and expressions. We first train a deep Convolutional NeuralNetwork (CNN) for landmark identification. CNNs have been extensively used for 2Dtexture images where the training data with ground truth labels is abundantly available.However, in case of 3D faces there is a dearth of training data that contains significantvariation in facial shape, ethnicity and expressions. Our Deep Landmark IdentificationNetwork (DLIN) is trained on synthetic 3D images generated from a commercial soft-ware (FaceGenTM) and is able to detect 11 biologically significant [28] facial landmarkswith high accuracy and efficiency. Next, we divide the 3D face into five Voronoi regionsaround a subset of these landmarks using geodesically evolved level set curves [29]. Asparse set of discriminative keypoints are detected within each region and used to elas-tically align the corresponding region shapes of two given faces. Dense correspondenceis then achieved through nearest neighbour matches between the region vertices of alltraining faces. Finally, a 3D deformable model is constructed from the densely corre-sponding faces and the correspondence information is transferred to unseen 3D facesby fitting the deformable model in an iterative optimization.
关于面向多姿态的人脸对齐的 3D 解决方案(3D dense face alignment,3DDFA)
摘要:人脸对齐技术是将人脸模型与图像进行拟合,提取人脸像素的语义含义,是CV社区研究的重要课题。然而,大多数算法设计的脸在小到中等的姿态(低于45◦),缺乏的能力对齐脸在大的姿态高达90◦。面临的挑战有三个方面:首先,常用的基于地标的人脸模型假设所有地标都是可见的,因此不适合用于剖面视图。其次,从正面到侧面,脸部外观在大的姿势中变化更明显。第三,在大的姿势中标记地标是非常具有挑战性的,因为隐形地标需要猜测。在本文中,我们提出了一种新的对齐框架,即3D密集人脸对齐(3D Dense Face alignment, 3DDF a),该框架通过卷积神经网络(convolutional neutral network, CNN)将密集的3D人脸模型拟合到图像上。我们还提出了在剖面视图中合成大规模训练样本的方法来解决第三个数据标注问题。在具有挑战性的AFLW数据库上的实验表明,我们的方法比最先进的方法取得了显著的改进。
Face alignment, which fits a face model to an imageand extracts the semantic meanings of facial pixels, hasbeen an important topic in CV community. However , mostalgorithms are designed for faces in small to medium pos-
es (below 45◦), lacking the ability to align faces in largeposes up to 90◦. The challenges are three-fold: Firstly, thecommonly used landmark-based face model assumes thatall the landmarks are visible and is therefore not suitablefor profile views. Secondly, the face appearance variesmore dramatically across large poses, ranging from frontalview to profile view. Thirdly, labelling landmarks in largeposes is extremely challenging since the invisible landmarkshave to be guessed. In this paper , we propose a solution tothe three problems in an new alignment framework, called3D Dense Face Alignment (3DDF A), in which a dense 3Dface model is fitted to the image via convolutional neutralnetwork (CNN). We also propose a method to synthesizelarge-scale training samples in profile views to solve thethird problem of data labelling. Experiments on the chal-lenging AFLW database show that our approach achievessignificant improvements over state-of-the-art methods.