基于深度学习的2维人脸特征点自动检测
基于级联卷积神经网络的方法
DCNN(deep convolu- tional neural network)
论文出处:Sun Y, Wang X G and Tang X O. 2013. Deep convolutional network cascade for facial point detection / / Proceedings of 2013 IEEE Con- ference on Computer Vision and Pattern Recognition. Portland, USA: IEEE: 3476-3483 [DOI: 10. 1109 / CVPR. 2013. 446]
进展:
1.将CNN应用到人脸特征点识别
2.提出了级联卷积神经网络
3.对于关键点初始化进行了创新,避免陷入局部最优的漩涡
4.借鉴了局部共享权值的概念,人的五官为定点位置出现,故不需采用全局权值共享
研究方法:
带有三级的级联卷积神经网络提取全局特征
级联卷积神经网络由三个level构成,level-1由三个CNN构成;level-2与level-3分别由十个CNN识别五个特征点但输入不同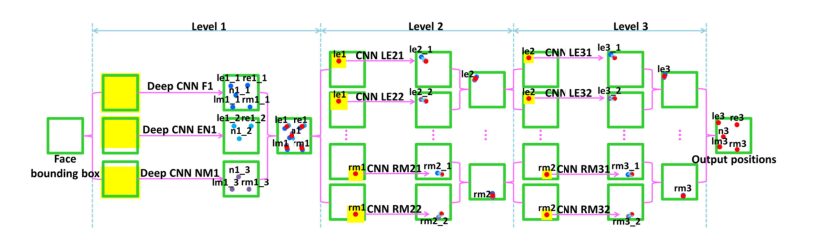
Level-1:三个CNN:F1(face 1)、EN1(eye,nose)、NM1(nose,mouth);F1的input3939,输出5个点;EN1input3931,输出是3个点;NM1的input3931,输出3个点。Level-1的输出是由三个CNN输出取平均得到
局部权值共享来源文献2012-CVPR Learning hierarchical representations for face verification with convolutional deep belief networks
*研究结果:
解决了容易陷入全局最优的问题,使用卷积神经网络的提取能力,由粗到细的级联回归,提高了检测精度
LSTM(long short-term memory)
优势:
以模型尺寸的名义上的增加显着增强了全卷积网络的性能,并且需要对数据集进行最少的预处理;通过注意力长期短期记忆完全卷积网络(ALSTM-FCN)改善时间序列分类;模型输入的通用性,因此它在多种序列建模任务(例如文本分析,音乐识别和语音检测)上具有广泛的适用性;由于其体积小,效率高,因此可以轻松地部署到实时系统或嵌入式系统中
基于深度端到端回归的方法
DeCaFA(deep convolutional cascade for face alignment)
进展:
为每一定位任务生成特征点注意图;加权中间监督以及各阶段之间的有效特征融合;允许学习以端到端的方式逐步完善注意图;训练数据集少且精度合理
研究方法:
采用端到端的深度全卷积级联结构保持全空间分辨率,使用多个具有空间softmax的链式转移层来为每个地标对齐任务生成地标式注意图。加权中间监督,以及各阶段之间的有效特征融合,允许学习以端到端方式逐步细化注意图。
基于自动编码器网络的方法
自动编码器(auto-encoder)
论文出处:Zhang C Q, Liu Y Q and Fu H Z. 2020. AE2-nets: autoencoder in autoencoder networks/ / Proceedings of 2019 IEEE / CVF Conference on Computer Vision and Pattern Recognition ( CVPR ). Long Beach, USA: IEEE: 2572-2580 [ DOI: 10. 1109 / CVPR. 2019. 00268]
进展:把来自异构视图的内在信息编码为一个全面的表示,并且自动的平衡不同视图的互补性和一致性
由内部AE网络编码重建原始视图的输入,然后由外部AE网络对内部AE网络的输出进行重构编码表示。
每个单一视图。本文的主要贡献概括如下:
•我们提出了一种新颖的无监督多视图表示学习框架 - 自动编码器网络中的自动编码器(AE2-Nets),用于异构数据,可以灵活地将多个异构视图集成到一个完整的表示中。
•新型嵌套自动编码器网络可以联合形成视图特定表示学习和多视图表示学习 - 内部自动编码器网络有效地从每个单个视图中提取信息,而外部自动编码器网络模拟降级过程进行编码从每个单一视图的内在信息到共同的完整表示。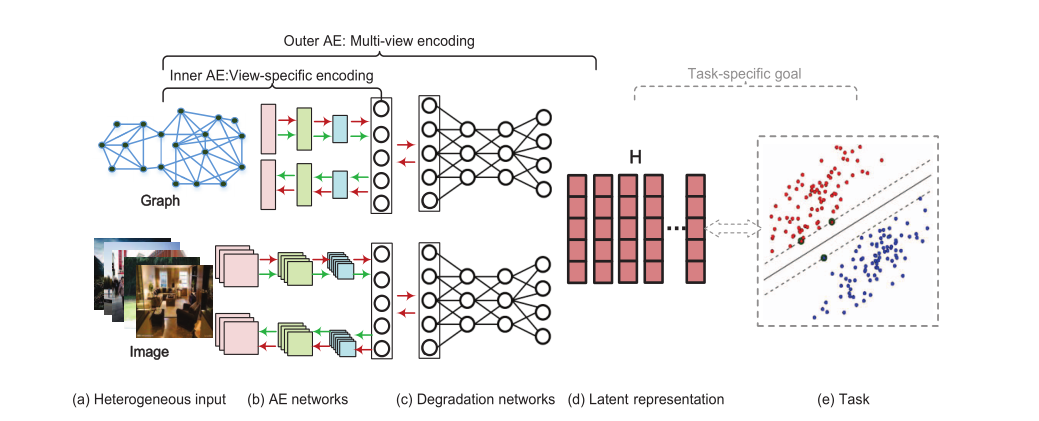
上图为算法核心表示,利用自动编码器思想
(1)式为autoencoder公式,一共M+1层,中间有M层的连接,前M/2层是encoder过程,即把图片降维为一个低维的表示,后面的M/2层就为decoder过程,即把已经降维的表示再升维为原来的维度,图(c)的降维就是获取了autoencoder的第M/2层,因为这一层就是中间的维度较低的那一层,用这一层表示肯定更简单一点,因为维度较低,然后用一个隐藏层H来表示这个M/2层,H作为隐藏层,先给H层赋任意值,通过loss function优化H,最终找到适合网络
代码具体执行过程:
1.先作autoencoder,做autoencoder时候优化的是autoencoder网络但是同时要计算encoder产生的中间层和gi(L,v)的loss,把autoencoder的loss和中间层和gi(L,v)产生的loss加起来优化autoencoder网络。
2.根据训练好的autoencoder网络,然后再优化H到中间层的网络
3.现在已知H到中间层的网络,反过来找一个最佳输入
4.循环执行前者
基于小滤波器的深度卷积神经网络(deep con- volution neural network with small filter, DCNNSF)
发展:
解决在复杂环境下,如姿势不同、光照条件以及遮挡等因素导致传统人脸特征点检测算法的精度大幅度下降的问题
有效减少参数的数量,避免了过拟合的问题,使模型达到更高精度和鲁棒性。
研究方法:
采用基于小滤波器的神卷积神经网络具体架构解决人脸5特征点预测问题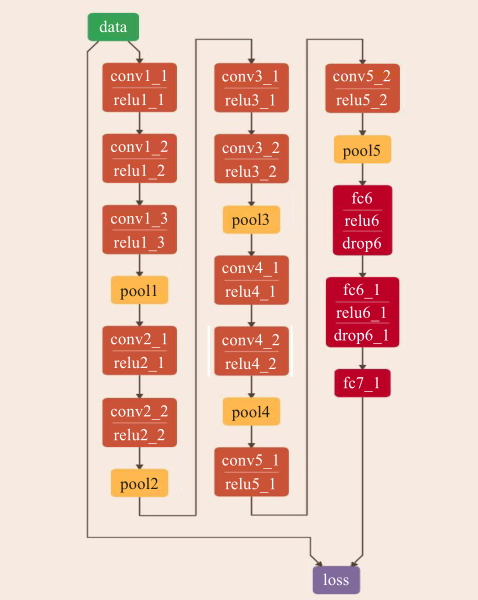
网络的 I(Data)层为网络输入层,该层为整个网络输入一张 128×128的三通道彩色图片。网络的 Conv1_1层为第 一个卷积层(ConvolutionLayer),该层由 32个特征图谱(Feature Map)构成。特征图中的每个单元与输入层的一个 3×3的相邻区域相连,卷积的输入区域大小是 3×3,因此特征图是由 32个大小为3×3的卷积核从输入图片中卷积得到,每个特征图谱内参数共享。其输出 32个大小为 128×128的特征图。网络的 Conv1_2层为第二个相连 3×3卷积层,该层输入信息为 Conv1_1层中输出的 32个大小为 128×128特征图信息,其输出 64个大小为 128×128的特征图。网络的 Conv1_3层为第三个相连 3×3卷积层,该层输入信息为 Conv1_2层中输出的 64个大小为 128×128特征图信息。它的作用是与 Conv1_1层、Conv1_2层叠加,从而替代大型 7×7卷积层,减少参数,并达到相同的卷积效果。该层最终将 96个大小为 128×128的特征图输出到下一层中。
网络的 Pool1层为第一个池化层(Pooling Layer),该层对输入的特征图进行压缩,首先可以使特征图变小,有效简化网络计算复杂度;其次对特征进行压缩,以便于提取主要特征。Pool1接收输入为 Conv1_3层 64个大小为 128×128的特征图信息 ,使用最大池化(Max Pooling),池化领域 2×2最大领域,由于步长为 2,所输出的特征图为 128/2 = 64个,数据规模为原来的 1/4,最终输出 96个大小为 128×128的特征图。其他卷积层与池化层的具体操作同 Conv1_1、Conv1_2、Conv1_3、Pool1层类似,每个大型的卷积层之间初始参数以 32、64、96、128、160的方式递增,除了第
一个大型的卷积层,其他大型卷积层中的 3×3小卷积层之间的参数都以倍增的形式增加。因此 Pool5层最终输出 320个 4×4的特征图。Conv6_1、Conv6_2与 Conv7层都为全连接层 。
Conv6_1层接收来自 Pool5输出的特征图信息,将其转化为一维向量,用来表示整个面部点,并将结果输出到Conv6_2层中,使模型表达能力和非线性表达能力得到增强,最终通过 Conv7层输出一维向量(如式(1)所示),其中 x、y代表 10个人脸坐标信息。
2维人脸特征点自动标定存在问题及发展趋势:
摘自:Xu Y L, Zhao J L, Lyu Z H, Zhang Z M, Li J H and Pan Z K. 2021. Automatic facial feature points location based on deep learning: a review. Journal of Image and Graphics,26(11):2630-2644(徐亚丽,赵俊莉,吕智涵,张志梅,李劲华,潘振宽. 2021. 深度学习人脸特征点自动定位综述. 中国图象图形学报,26(11):2630-2644)[DOI:10. 11834 / jig. 200278]
在 2 维图像数据中,具有真实特征点标签的训练数据非常丰富。针对 2 维数据的特征点自动定位方法的研究已比较深入,包括级联卷积神经网络、深度端到端回归网络、自动编码器网络及其他改进CNN的网络,已取得较为理想的效果,并在人脸识别和人脸编辑等实际任务中广泛应用。 存在的主要问题和未来发展趋势包括以下方面:
1)从特征提取角度入手,使用自动学习更符合人脸图像的特征来优化特征点定位性能。
2)端到端的学习不需要手动标注但需要依靠大量数据,适用于大规模的数据集。所以端到端的方法可以从数据增强、数据生成以及如何构建小样 本深度学习网络结构方面继续研究。
3)自动编码器依据特定的样本进行训练,因此 其适用性很大程度上局限于与训练样本相似的数据且很容易过拟合,如何降低时间复杂度、避免陷入局 部最小值是亟待解决的问题。
4)对于姿态变化较大的图像,如何更好地处理姿态、初始化以及减少计算成本仍然值得探讨。综上所述,针对 2 维数据的人脸特征点自动标定研究,需要从网络结构、数据增强、特征选取和 初始化等方面创新。 同时,减少数据集的局限性、避免过拟合和减少时间复杂度也是需要考虑的问题。