(基于深度学习的3维人脸特征点自动检测)
将3维模型转化为2维图像的方法
Deep landmark identification network, DLIN
结论:
·提出一个多线性算法自动建立密集的点对点对应的任意数量的3D人脸,提出深度特征点识别网络对合成图像进行训练。
·使用DLIN检测显著特征点,使用它们通过水平集曲线生产测地线距离图将3D人脸分割为Voronoi区域;利用这些区域中的·关键点以非刚性的方式对人脸中的相似区域进行对齐,通过神经网络搜索建立密集对应关系。
·提出一种基于区域的三维可变型模型(R3DM),以有效地将密集的通信传播到大型数据集。
·不依赖于现有的3D人脸模型。
·论文原意将其应用于对诸如睡眠呼吸暂停症和自闭症谱系障碍等疾病进行表型分析。
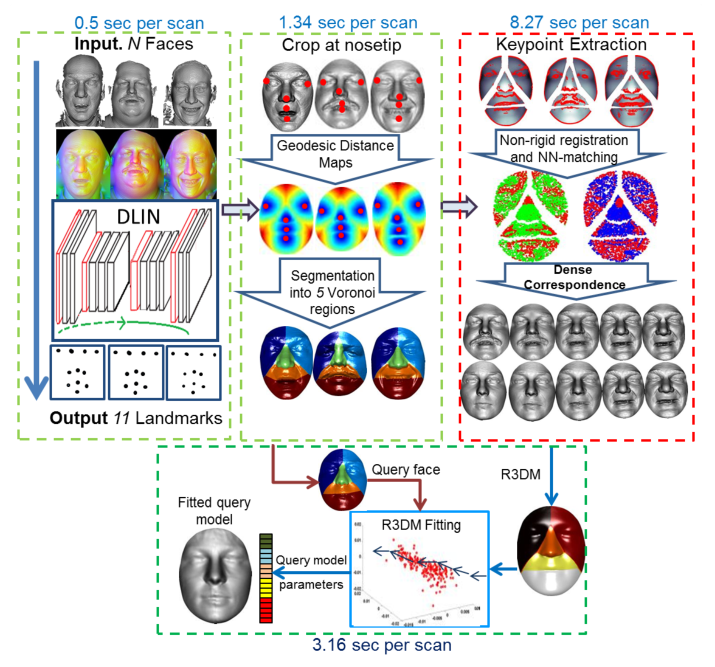
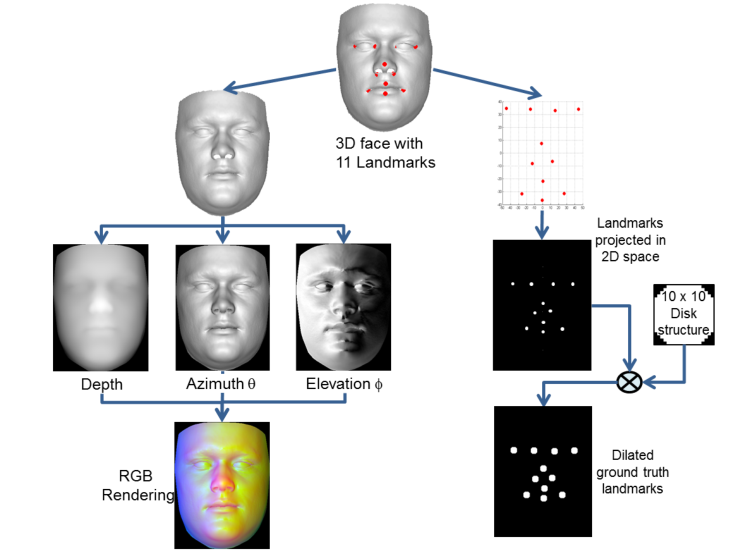
1.生成合成训练数据
为了训练深度地标识别网络(DLIN),作者使用商业软件(FaceGenTM),通过改变面部形状和面部表情,综合生成真实的3D人脸。因为人脸是由模型生成的,所以特征点的真实位置就已经知道了。训练数据覆盖了由于年龄、种族和表情而导致的面部形状变化的巨大空间。还在训练数据中诱导姿态变化,以适应测试图像中的姿态变化。
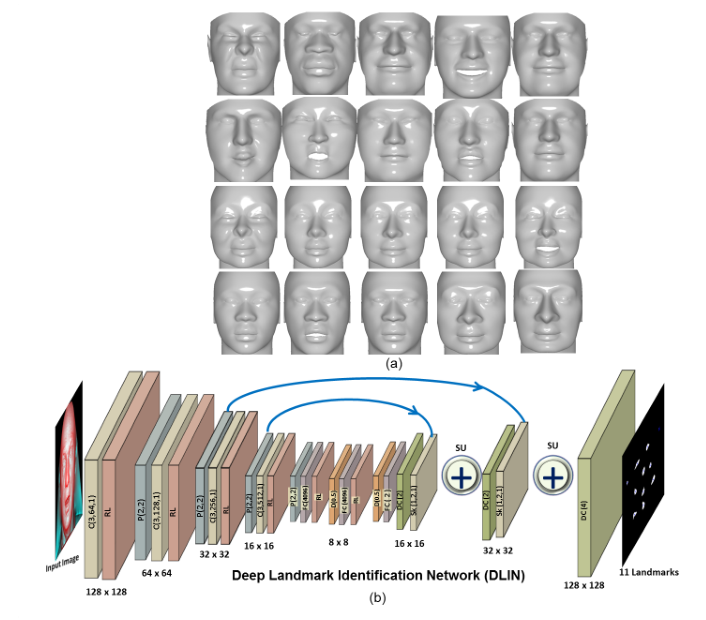
2.训练深度特征点识别网络
卷积层数为5层,上采样层改为4x层
实验表明,减少8个卷积层可以使学习时间减少约3倍,特征点检测时间减少4倍。
3.使用DLIN进行特征点检测

基于区域的密集对应
原因:医学应用中,特征点检测和对应的准确性至关重要,密集的对应必须非常精确.
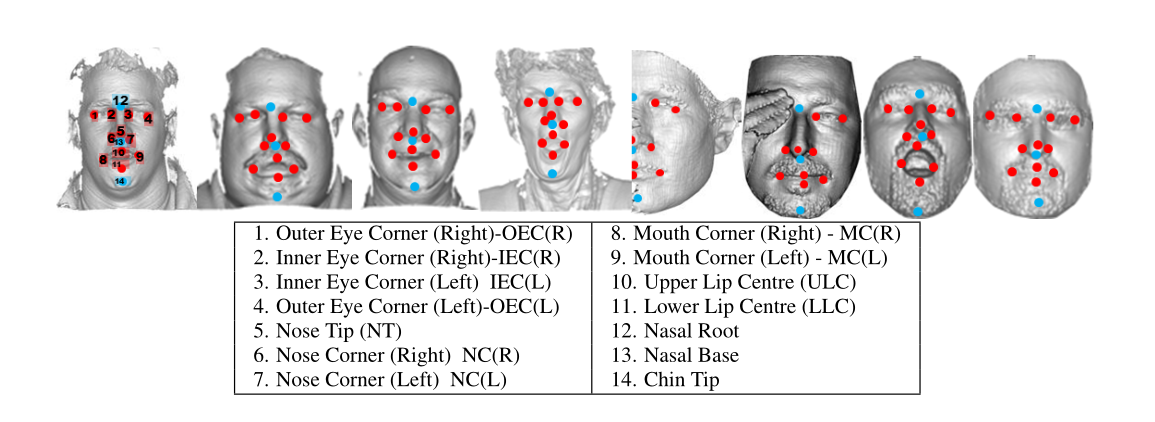
输入:一组用Fj表示的N个3D人脸及其对应的基准特征点Lj
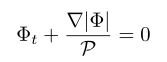
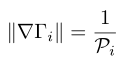
通过计算最短曲面距离(又称为geodesic distance)利用Fsat Marching算法求解的LHS,找到了geodesic distance距离映射,然后将3D人脸划分为五个特征点相关的区域
——关于可形变模型拟合
R3DM:通过可变形模型拟合将密集对应传播到大量的查询面,比建立基于区域的对应更快
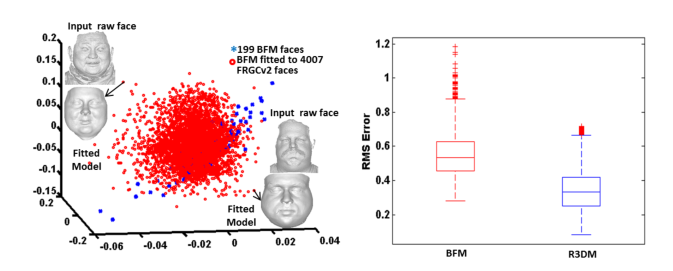
作为验证密集通信算法质量的一种方法。
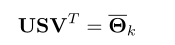
US为主成分(PCs),V列为对应的荷载
人脸通过DLIN特征点识别,分为五个面部区域,R3DM和查询人脸的鼻尖剧中,实现初始人脸对齐。通过上式给出的各区域统计模型进行变形,合成查询人脸区域内三位点随即子集,进行两步优化(矢量化查询和刚性变换)。最后将所有区域参数串联起来,作为表征人脸的特征。
具体实验
合成数据集训练DLIN,实验在真实的3D人脸数据集进行。
使用数据集:基准的FRGCv2和Bosphorus数据集
DLIN与FCN的比较:为了评估DLIN在FCN上的改进,作者遵循相同训练协议。更具体地说,DLIN是从零开始学习的,而FCN是在相同的训练数据上进行微调的。在4,007张FRGCv2扫描图上测试了这两种网络,并比较了地标定位误差和每幅图像的检测时间。从结果可以看出,DLIN的地标检测速度比FCN快4倍,而对所有地标的精度都等于或略优于FCN。
作者在不同数据集上进行测试并给出比较结果。例如,在博斯普鲁斯数据集上使用类似的策略,对未见过的面孔进行无偏地标检测。DLIN探测到的11个地标的精度在2.95mm和1.83mm之间,从而将精度提高了30%。结果表明,该方法具有较高的精度和对大姿态和表情变化的鲁棒性。
构建了两个模型R3DM1和R3DM2。
We presented an algorithm for dense correspondence over a large number of 3D faces across varying facial expressions and identities. We trained a Deep Landmark Identification Network (DLIN) using synthetic images to detect salient landmarks and used them to segment the 3D face into Voronoi regions by generating a geodesic distance map through level set curves. Keypoints in these regions were used to align similar regions across faces in a non-rigid manner and dense correspondence was established through NN search. We also proposed a Region based 3D Deformable Model (R3DM) to propagate the dense correspondences to large datasets efficiently. Experiments on benchmark datasets with challenging protocols show that our algorithm is faster and more accurate than existing state-of-the-art. Our algorithm is able to generate population specific accurate deformable 3D face models from scratch without relying on existing linear 3D face models such as the BFM. In the future, we intend to use our algorithm for phenotyping medical conditions such as Sleep Apnoea and Autistic Spectrum Disorder.
我们提出了一种算法,用于在不同面部表情和身份的大量3D人脸上进行密集通信。我们使用合成图像训练深度地标识别网络(DLIN)来检测显著地标,并使用它们通过水平集曲线生成测地线距离图将3D人脸分割为Voronoi区域。利用这些区域中的关键点以非刚性的方式对人脸中的相似区域进行对齐,通过神经网络搜索建立密集对应关系。我们还提出了一种基于区域的三维可变形模型(R3DM),以有效地将密集的通信传播到大型数据集。在具有挑战性协议的基准数据集上的实验表明,我们的算法比现有的最先进的算法更快、更准确。我们的算法能够从无开始生成特定人群的精确可变形3D人脸模型,而不依赖于现有的线性3D人脸模型(如BFM)。在未来,我们打算用我们的算法来对诸如睡眠呼吸暂停症和自闭症谱系障碍等疾病进行表型分析。
思路:首先对三维人脸建立稠密准确的密集对应联系,据此组合不同身份和不同表情的人脸进行数据集的身份和表情扩增;也采用了HPR算法对旋转人脸的自遮挡进行了模拟,据此进行了数据集的姿态扩增。通过以上方法构建了一个百万级的三维人脸数据集,然后利用GridFit算法插值得到深度,俯角和仰角的三通道图像,从头训练了一个神经网络,在目前所有的公开三维人脸数据集中获得了非常好的成绩。
基于3维形变模型的方法
3D morphable models,3DMM
算法主要流程
从上面的叙述中,我们可以直观的想象,主要有两个步骤,第一个是从人脸数据库中所有脸构建出一个平均的脸部模型,第二个完成形变模型与照片的匹配。这两个步骤中,都暗含了人脸与人脸之间的每一个点都拥有对应关系,且必须找到这种对应关系,完成点与点之间的配准,是最主要的难题。
因此在进行建模的过程中,需要完成以下两个关键的问题:
模型与照片的配准
如何避免生成怪异不可能的模型
文章主要组织为以下几部分对思路进行介绍:
三维形变的脸部模型
这里作者将人脸分为了两种向量:
一种是形状向量(shape-vector),包含了X , Y , Z 坐标信息;另一种是纹理向量(texture-vector), 包含了R , G , B颜色值信息
在有了以上的表示方法后,我们使用的建立三维形变的脸部模型由m mm个脸部模型组成,其中每一个都包含相应的$S_{i}, T_{i} $两种向量。
将形变模型与照片对应
在有了形变模型之后,对于一张给定的人脸照片,我们需要将模型与人脸照片进行配准,然后对模型的参数进行调整,使其与照片中的人脸差异值达到最小。简单而言,不断依据模型与输入的人脸照片进行比对,不断进行迭代,使两者之间的比对误差达到最小,这个时候,我们可以近似认为该模型即为对应输入的人脸照片的三维模型。
3D dense face alignment,3DDFA
Face Alignment
Face Alignment 人脸对齐任务是基于一定量的训练集,得到一个模型,使得该模型对输入的一张任意姿态下的人脸图像能够进行特征点(landmark)标记。Face Alignment 任务一般的呈现方式是人脸特征点的检测与标记。一般的二维人脸图像 Face Alignment 得到的结果是特征点的二维位置坐标信息。
Full pose range
文中将人脸转动角度小于45度的姿势称为 small-medium pose,对于转动角度大于45度,小于等于90度的姿势称为 large pose。即,此篇论文解决的问题是大姿势下的人脸对齐任务。最极端情况则是整张人脸图像上只有侧脸信息。
通用的一些FA模型在大姿势的情况下会面临一些挑战:
这些模型假定所有的特征点可见;
随着姿势的变化,人脸呈现的角度也会发生变化,在大姿势的情况下无法保证所有特征点可见;
不同的姿势带来的特征点标记困难程度也会上升,而对于一些不可见的点,现有的办法大部分是靠猜。
3DDFA(3D Dense Face Alignment)
问题的转换
将常见的2D人脸特征点标记问题转换为3D拟合的任务。具体表现在需要求解的参数上。
2D人脸特征点标记得到的结果:一系列2D特征点位置坐标
3D拟合需要求解的参数
pose 姿势参数:scale 缩放因子, rotation 旋转矩阵, translation 平移向量
morphing 变形参数: shape 形状系数, expression 表情系数
人脸形状的表示——3DMM
选择3DMM对人脸形状进行表示。在传统3DMM的基础上,加入3DMM拓展模型的 identity 和 expression 参数。那么,人脸形状 S的表示方式如下: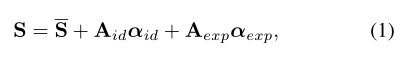
其中,S 表示平均人脸形状,A 表示主成分向量,α 表示相应的系数。
参数估计方法——级联回归+CNN
级联回归:通过一系列回归器将一个指定的初始预测值逐步细化,每一个回归器都依靠前一个回归器的输出来执行下一步操作。联系到FA任务中,则是基于初始人脸形状,一般选择的是平均人脸形状,通过多次回归把参数回归到ground-truth的地方。
卷积神经网络CNN:将人脸特征点标记看作从图像像素到特征点位置的回归操作。
3DDFA方法则是将级联回归中的回归器设置为CNN。
根据这个式子,需要了解的主要是四个部分:
·回归目标,即参数p
·卷积神经网络的输入,即图像特征Fea的设计
·卷积神经网络的设计,即Net
·代价函数的设计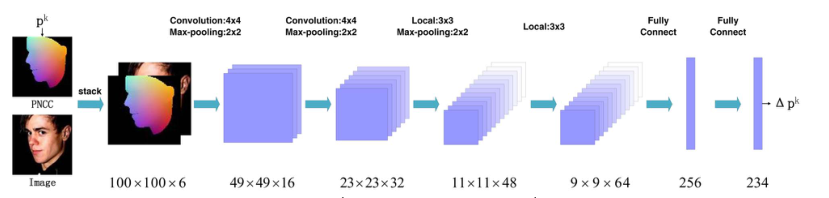
这篇论文主要是将二维的人脸特征标记问题转为了二维图像与三维模型的拟合问题。主要是通过级联的卷积神经网络,将二维人脸图像与三维变形模型进行拟合;使用3D变形模型构建得到的三维人脸并映射到二维人脸图像上的结果。
重点还是在于大姿势人脸的一个三维重建,主要学习的也是三维映射所需要的各种参数。从而使得正面的三维人脸在映射过程中随着各个参数的变化而转变人脸呈现的角度。
Deep face feature,DFF
本文基于深度学习的图像特征提取方法
提出了一个由三个卷积网络组成的从粗到细的学习框架,经过训练可将
深度人脸特征(DFF)是使用不同视图渲染的人脸图像之间的对应关系进行训练的。
使用经过训练的DFF模型,可以为人脸图像的每个像素提取特征向量,从而区分不同的人脸区域,并被证明比通用的特征描述符更有效的人脸相关任务,如匹配和对齐。
使用CNN提高回归精度,对于人脸图像的每个像素,使用该模型提取一个高维特征,该特征可以在无约束条件下准确地表示不同人脸图像上的相同解剖面部点
·使用一个构造良好的训练数据集和一个新的损失函数
·利用新设计的人脸特征提取器
本文介绍了传统的经典人脸对齐方法,提出它们在不同视角下的局限性。
DFF是一种基于深度学习的人脸特征提取方法,利用不同姿势和表情下的对应关系,得到不同人脸图像中相同语义像素的深度人脸特征具有相似的值。因此,DFF能够捕获人脸图像的全局结构信息,在匹配、对齐等人脸相关任务上比SIFT等常用特征描述符更有效。作者提出了一种新的基于DFF的人脸对齐方法,实现了最先进的大姿态人脸对齐结果。