FaceGen的使用
(接上篇)
FaceGen Modeller与FaceGen 3D Print可以使用其他很多格式进行导出与查看
以下为三款程序之间的对比:

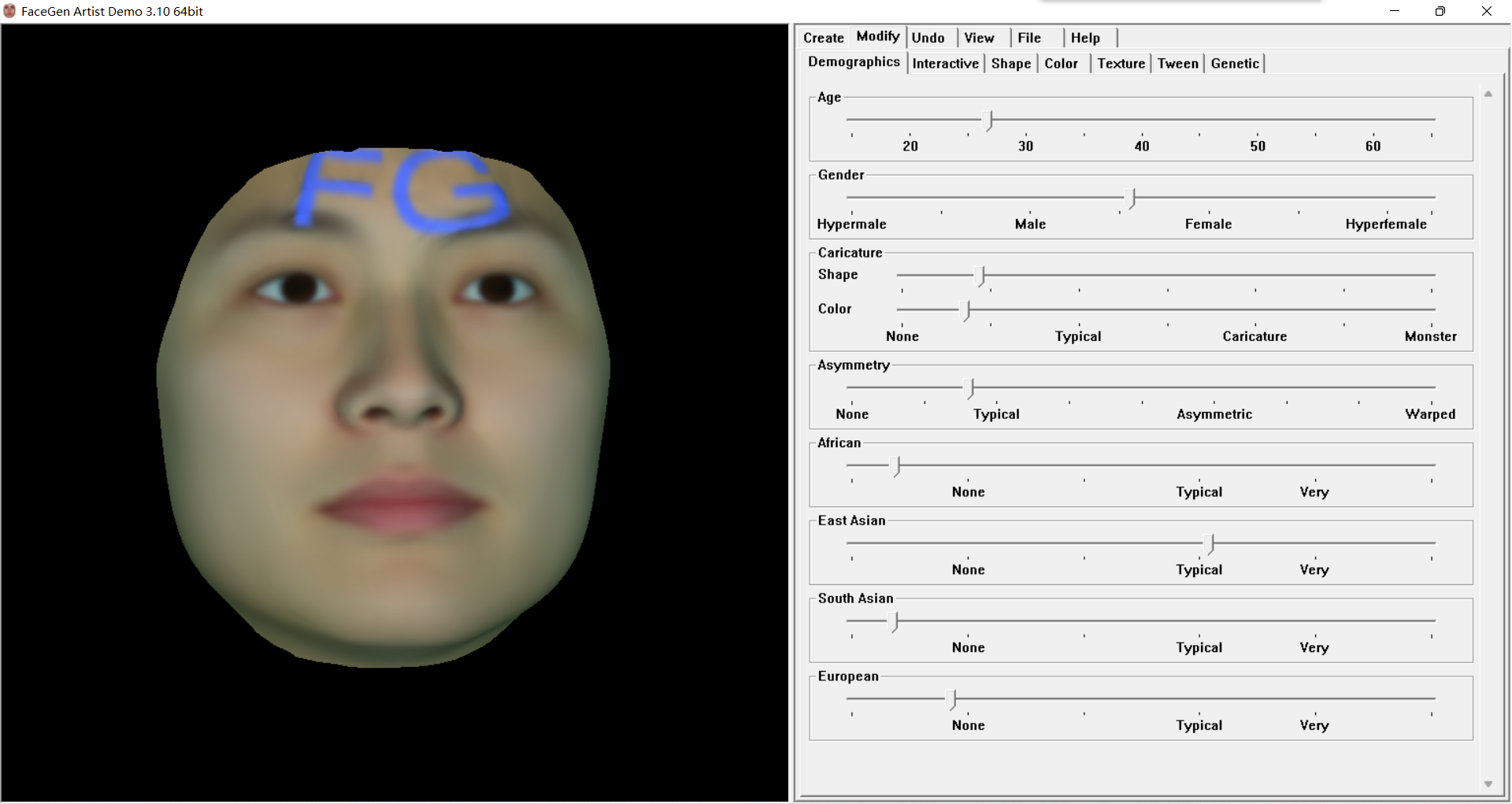
FaceGen Artist支持直接导入图片自动生成人脸模型,支持多张人脸图片的组合,允许调整人脸的各种细节(包括年龄、性别、种族、肤色、皱纹、痣,头发和许多其他参数),直到达到您想要的效果,依此类推。
非常易于使用。您只需导入您要调整的正确脸部照片,然后软件将分析图像并创建新的脸部网格以及相应的整体皮肤纹理。创建好的人脸模型可以直接导入DAZ Studio使用。此外,它还支持连接3D打印机程序进行打印操作。
FaceGen Artist细节处理非常细致,五官的处理非常精准。它可以帮助用户轻松调整整张脸的各种细节,从而完美完成整张脸模型的设计和调整,让人物形象更加生动。
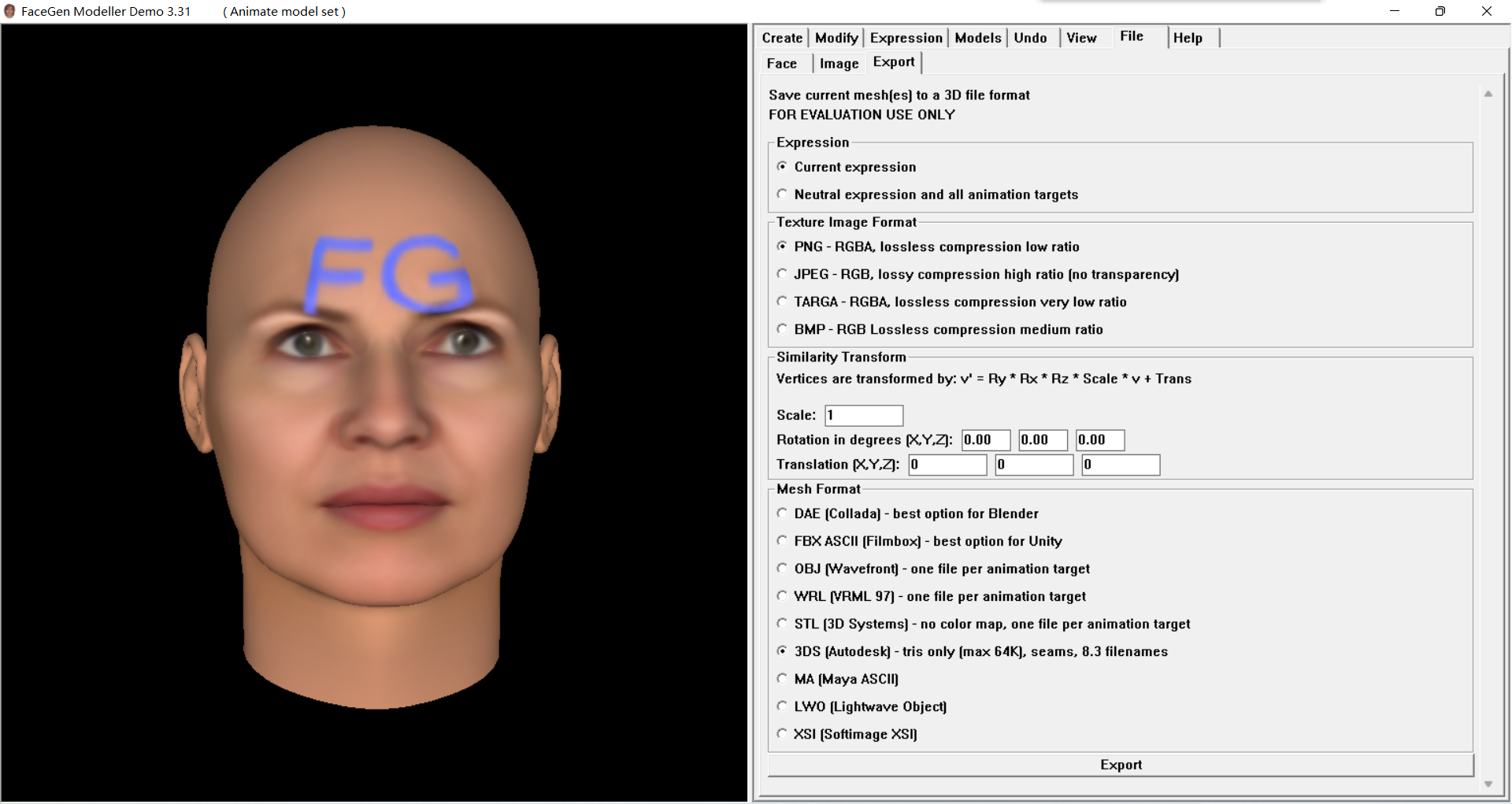
FaceGen Modeller 作为一款小巧易用、功能强大、高效的 3D 人脸建模工具,可以随机或从照片中创建 3D、逼真的人脸,支持多种面部细节的调整,包括种族、性别、年龄、眼睛、眉毛、鼻孔等150多个五官。此外,它采用带有表情和色调的动画形式实时显示结果,可以存储为BMP、JPG、TGA、TIF等格式的图像,也可以导出为FBX、OBJ、3DS、WRL等3D 文件格式。
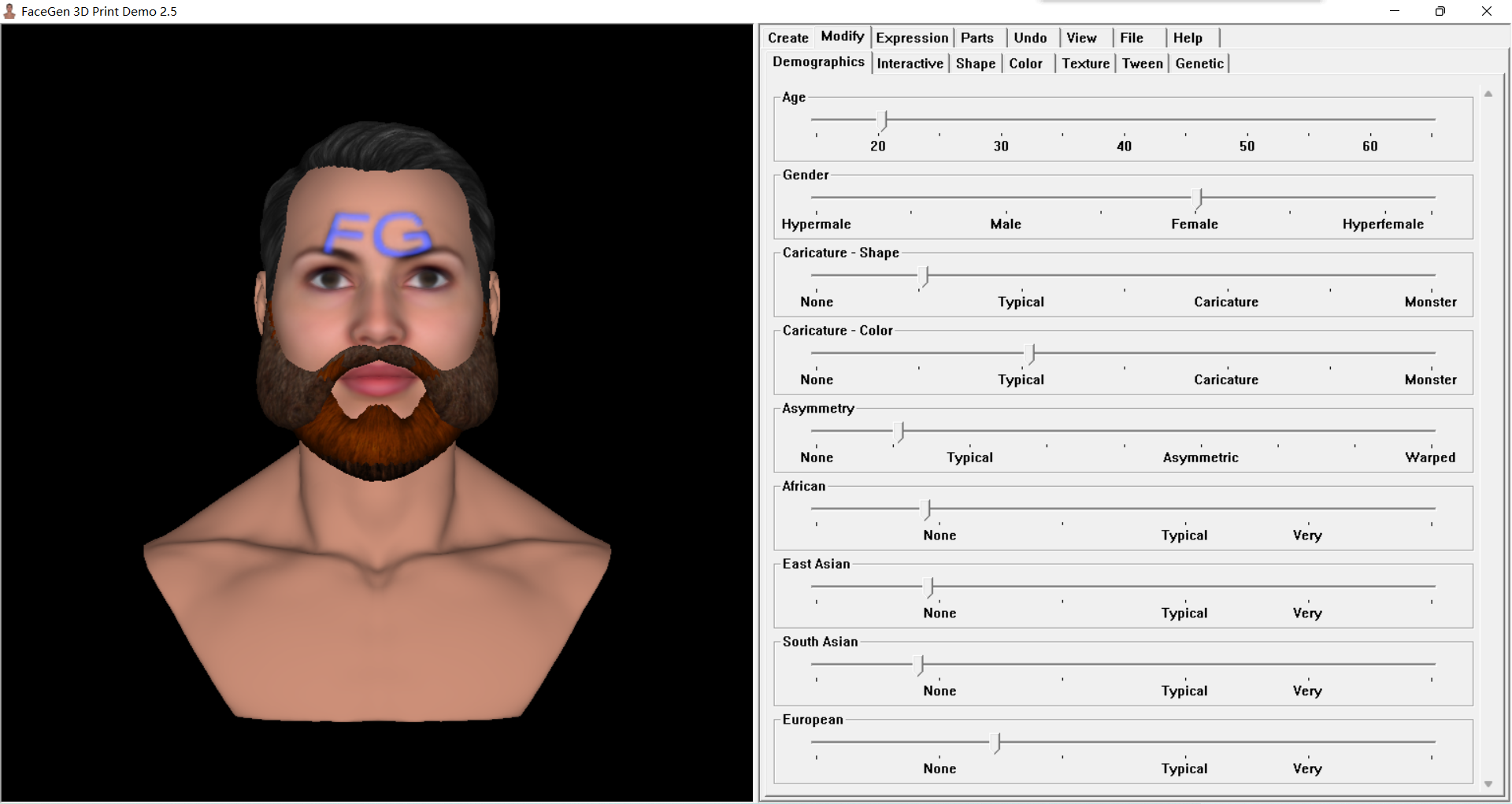
FaceGen 3D Print Demo塑造一个有底座的头部人像,导出格式支持PNG,JPEG,TARGA,BMP文件格式。
Towards Fast, Accurate and Stable 3D Dense Face Alignment
关于快速,准确和稳定的三维密集人脸对准
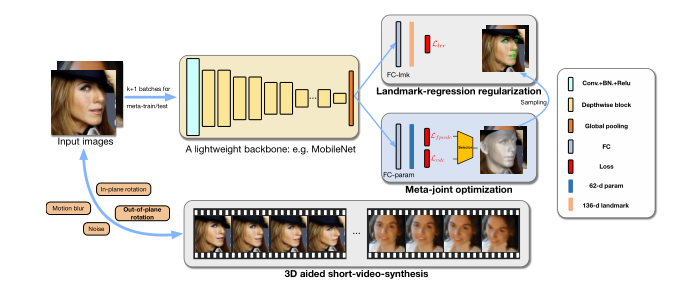
1.采用轻量级的网络模型回归出3DMM的参数(论文2.1节),然后为该网络设置了meta-joint optimization优化策略(论文2.2节),动态的组合wpdc(Weighted Parameter Distance)和vdc(Vertex Distance Cost)损失函数,从而加速了拟合的速度,也使得拟合的效果更加精确
2.提出landmark-regression regularization(特征点回归正则化)来加速拟合的速度和精确度
3.为了解决在video上的三维人脸对齐任务(相邻帧之间的三维重建更加稳定,快速,连续性),在基于video数据上训练的模型,但video视频数据库缺乏时,提出了3D aided short-video-synthesis(三维辅助短视频合成技术),将一个静止的图片在平面内还有平面外旋转变成一个短视频
3DMM
1.回归参数截取
2.参数的归一化处理
3.3D人脸与2D人脸之间的公式只差一个正投影P参数
损失函数设计
设计fWPDC

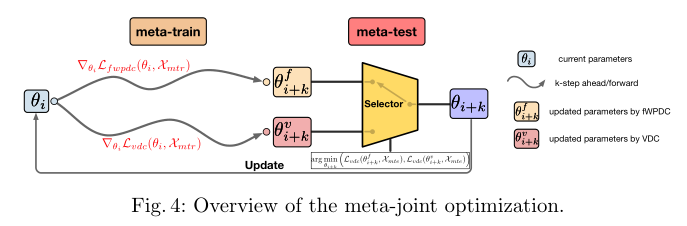
在使用fwpdc损失函数训练好模型后,然后保存此次模型的训练结果;之后开始进行下次训练,在训练前,将模型的参数初始化为上次保存的模型,然后在使用vdc损失函数继续对该模型进行训练!
基于这种发现,提出了meta-joint optimization ,即动态的组合fwpdc和vdc损失函数进行训练。
3D Aided Short-video-synthesis(三维辅助短视频合成技术)
经测试发现,该技术共有两个作用; 一是对模型的训练有促进作用(用NME来衡量模型是否优越,可用21,68,NK个三维特征点之间的距离损失来计算dist);二是促进了在视频上进行三维人脸重建时候的稳定性(用相邻帧之间的偏移差异来衡量视频中三维人脸重建的稳定性)
3DFFA_V2代码的实现
首先,附属代码未提供测试与训练的代码,只提供了训练好的模型并将其储存
关于定义204[3, 64]个点,为什么要定义u_base , w_sha_base , w_exp_base的说明
(此解释 by CSDN 博主 LX-CV提供)
1 | # 在行上链接形状向量基于表情向量基,维度为[53215x3,50] |
obj文件: 将人脸保存为obj文件 即保存了这个特征点的形状属性,又保存了这个点的纹理属性(r1, g1, b1) ;
ply文件:将人脸保存为ply文件, 只保存了这个特征点的形状属性(x1, y1, z1),不保存纹理属性;
Faceboxs边界框检测器:
(本代码 by CSDN 博主 LX-CV提供)
facebox检测器传入人脸照片,返回的是个列表,用来存储边界框bbox(是个列表,共有5个数据),有几个人脸就有几个边界框 ; 接下来可以利用bbox边界框获得roi_box参数,然后便可以利用roi_box参数画出边框或者精确的剪切出人脸照片
1 | import sys |
挂vpn会出现无法pip的情况
Windows上运行需修改部分代码与函数,包括但不仅限于:
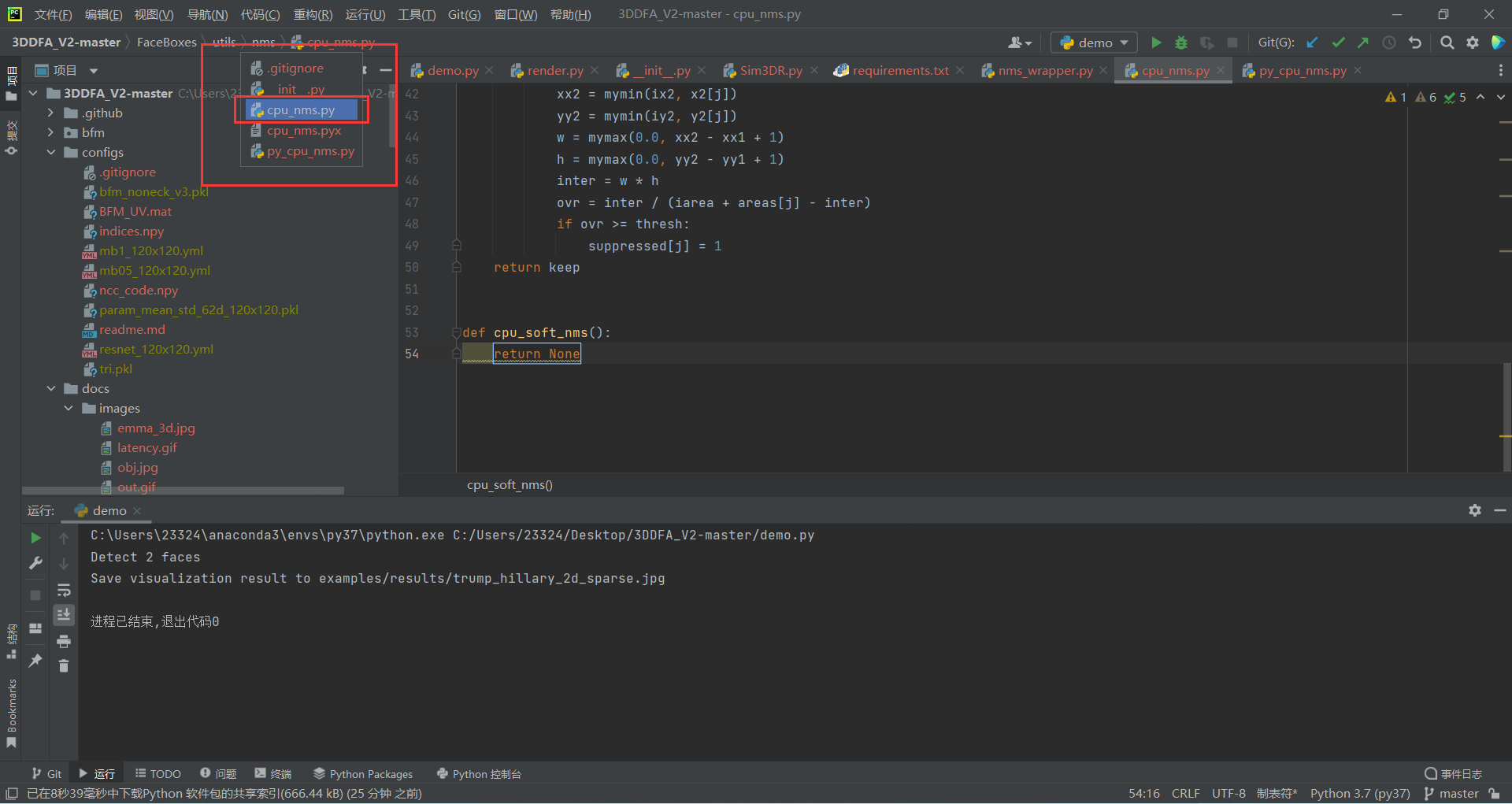
运行效果如下:
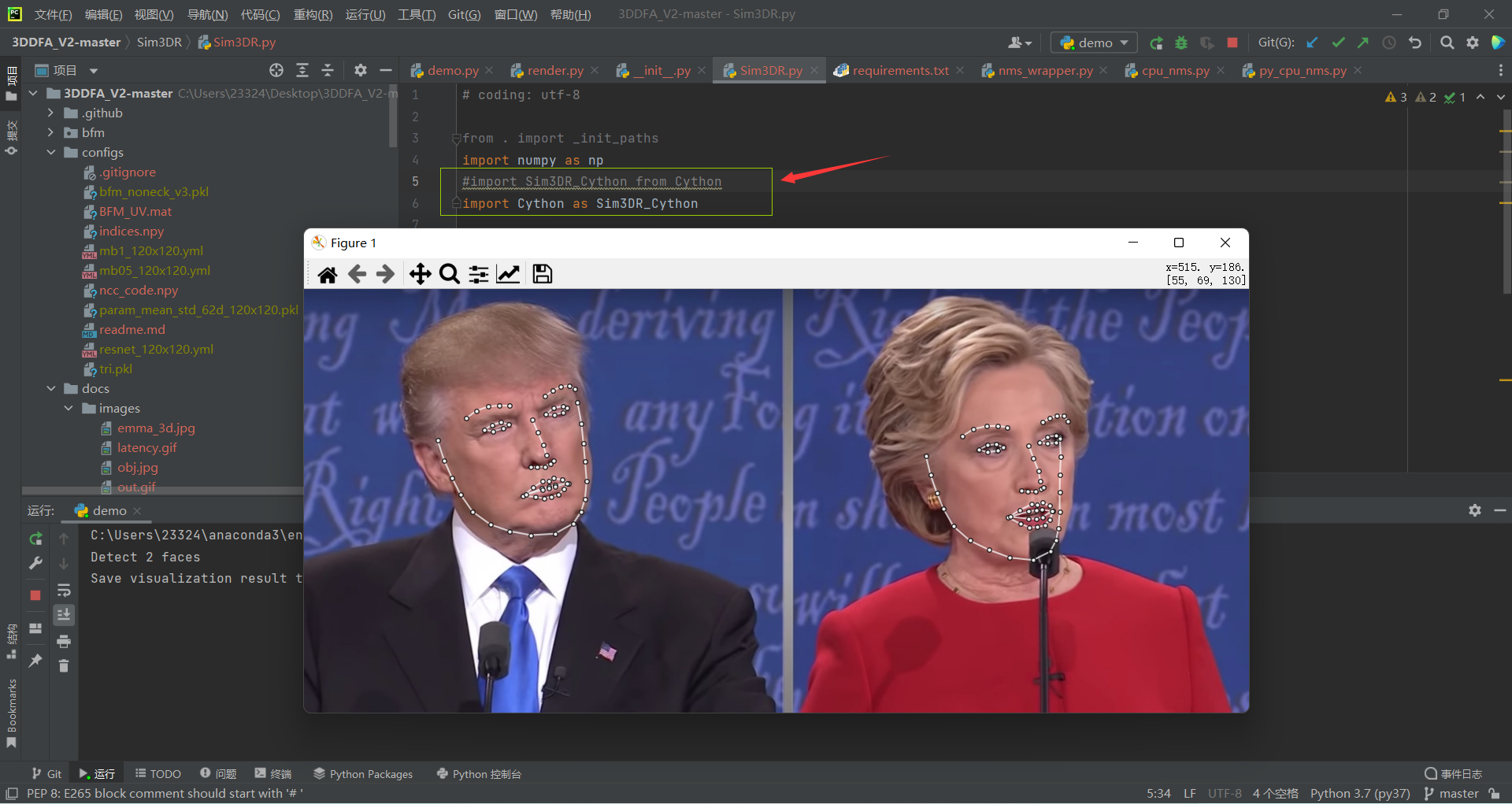

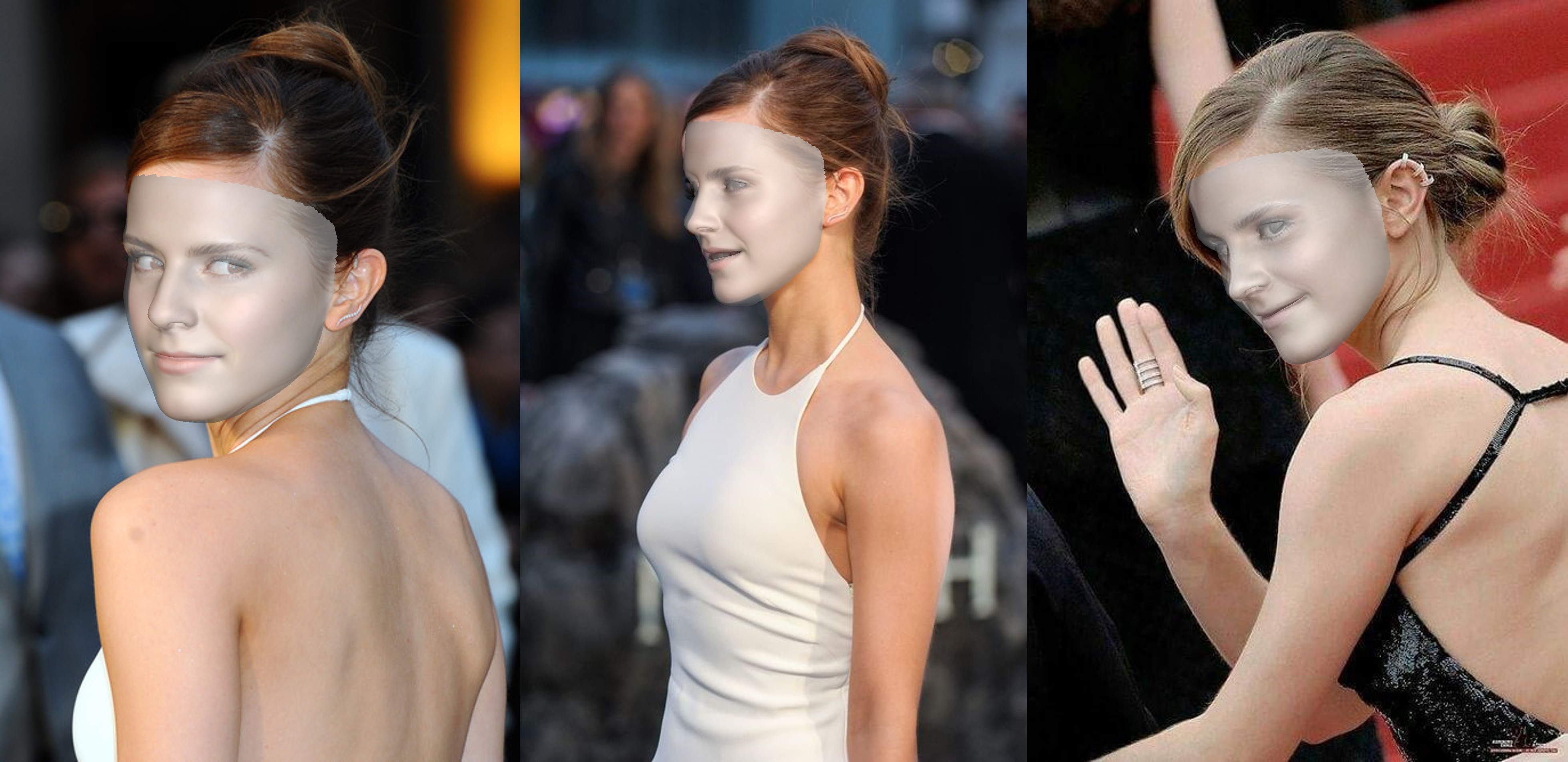





仍建议使用Linux或MacOS运行