shap-e
提出一种新的条件生成模型——Shap-E,用于生成3D图像。
探讨了如何在大数据集上训练Shap-E模型。
Shap-E模型的关键思路是通过两个阶段的训练来生成3D图像。首先,通过编码器将3D图像映射到隐式函数的参数空间中,然后在编码器的输出上训练有条件的扩散模型。相比于当前3D生成模型的研究状况,Shap-E模型的思路更加直接,可以生成复杂多样的3D图像,并且收敛速度更快。
两种用于3D表示的INR:
NeRF:将3D场景表示为将坐标和观看方向映射到密度和RGB颜色的函数。NeRF可以通过查询相机光线的密度和颜色从任意视图渲染,并训练以匹配3D场景的地面真实渲染。
DMTet /GET3D
ImageDream
一种创新的图像提示、多视角扩散模型,用于生成3D物体。
优势:能够产生更高质量的3D模型
解决问题:如何利用图像生成高质量的3D物体模型,同时提高视觉几何精度。
关键思路:使用标准的相机坐标系来提高图像中物体的几何精度,并在扩散模型内的每个块中设计不同级别的控制,以精细调整图像细节。
HarmonyView
先验知识
NeRF
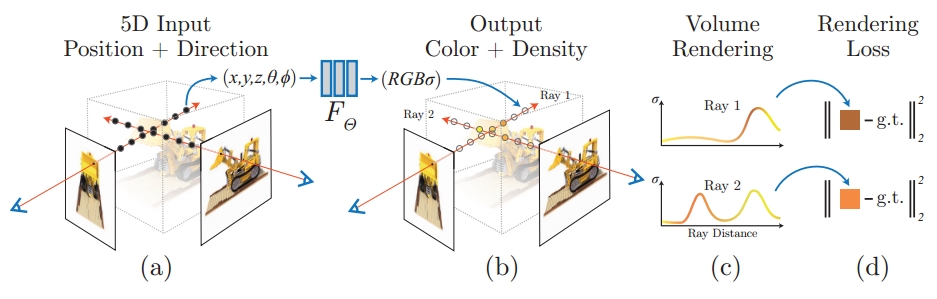
Neural Radiance Fields神经辐射场:仅用2D的posed images作为监督,即可表示复杂的三维场景。
处理的任务:新视角合成。**输入图像序列和位姿,输出**新视角&mesh
传统三维重建两种重建方式:
- 主动式
在传统的主动式三维重建中,首先从不同角度拍摄待重建物体的深度图像,由于彩色图像有助于相机定位及给模型添加颜色,也可以在采集深度图像同时,采集对应的彩色图像。随后通过ICP(Iterative Closest Point)等技术计算相机姿态。之后将场景隐式表达为SDF体素网格模型,最后通过raycasting渲染出重建的视角,最后输出给AR设备显示。
- 被动式
传统的被动式三维重建中,首先从不同角度拍摄待重建物体的彩色图像,随后通过SfM(structure from motion)等技术获得相机位姿和模型的初始点云。随后通过深度估计、点云的稠密重建、网格重建及优化和网格贴图等流程得到最终带有贴图的模型。
缺点:最终重建的模型中可能会有孔洞、纹理混叠、由于体素分辨率限制丢失很多细节。
NeRF的优势:合成照片级别的新视角,重建的模型细节更加丰富,它通过使用稀疏的输入视图集优化底层连续的体积场景函数,实现了综合复杂场景视图的最好结果,无空洞、细节还原,发展迅速。
CLIP
Contrastive Language-Image Pre-training 基于对比文本-图像对的预训练方法/模型
用户草图:结合HED边界检测和一组强数据增强(随机阈值、随机屏蔽涂鸦、随机形态变换、随机非极大抑制),从图像中合成人类涂鸦。从互联网上获得了50万对的涂鸦图像-caption数据对。使用前面的Canny模型作为初始化checkpoint,并使用Nvidia A100 80G用150个gpu小时训练。
工作原理和流程:
- 输入图像处理:TripoSR接受单张RGB图像作为输入。
- 图像编码器:使用预训练的视觉变换器模型(如DINOv1)将输入图像编码为一组潜在向量。这些向量包含了图像的全局和局部特征,为重建3D对象提供了必要信息。
- 图像到三平面(Triplane)解码器:将潜在向量转换为三平面-神经辐射场(NeRF)表示。平面-NeRF是一种紧凑且富有表现力的3D表示方法,适合表示具有复杂形状和纹理的物体。
- NeRF模型:由多层感知器(MLPs)堆叠而成,负责预测空间中3D点的颜色和密度。\
- 渲染和训练:模型在训练过程中不依赖于相机参数,而是在训练和推理时“猜测”相机参数,以增强模型对野外输入图像的鲁棒性。