2021 ICM
Problem D: The Influence of Music
题目原文
Music has been part of human societies since the beginning of time as an essential component of cultural heritage. As part of an effort to understand the role music has played in the collective human experience, we have been asked to develop a method to quantify musical evolution. There are many factors that can influence artists when they create a new piece of music, including their innate ingenuity, current social or political events, access to new instruments or tools, or other personal experiences. Our goal is to understand and measure the influence of previously produced music on new music and musical artists.
Some artists can list a dozen or more other artists who they say influenced their own musical work. It has also been suggested that influence can be measured by the degree of similarity between song characteristics, such as structure, rhythm, or lyrics. There are sometimes revolutionary shifts in music, offering new sounds or tempos, such as when a new genre emerges, or there is a reinvention of an existing genre (e.g. classical, pop/rock, jazz, etc.). This can be due to a sequence of small changes, a cooperative effort of artists, a series of influential artists, or a shift within society.
Many songs have similar sounds, and many artists have contributed to major shifts in a musical genre. Sometimes these shifts are due to one artist influencing another. Sometimes it is a change that emerges in response to external events (such as major world events or technological advances). By considering networks of songs and their musical characteristics, we can begin to capture the influence that musical artists have on each other. And, perhaps, we can also gain a better understanding of how music evolves through societies over time.
Your team has been identified by the Integrative Collective Music (ICM) Society to develop a model that measures musical influence. This problem asks you to examine evolutionary and revolutionary trends of artists and genres. To do this, your team has been given several data sets by the ICM:
1) “influence_data” 1 represents musical influencers and followers, as reported by the artists themselves, as well as the opinions of industry experts. These data contains influencers and followers for 5,854 artists in the last 90 years.
2)“full_music_data”2 provides 16 variable entries, including musical features such as danceability, tempo, loudness, and key, along with artist_name and artist_id for each of 98,340 songs. These data are used to create two summary data sets, including:
a.mean values by artist “data_by_artist”,
b.means across years “data_by_year”.
1 These data were scraped from AllMusic.com
2 These data were obtained from Spotify’s API
Note: DATA provided in these files are a subset of larger data sets. These files CONTAIN THE ONLY DATA YOU SHOULD USE FOR THIS PROBLEM.
To carry out this challenging project, the ICM Society asks your teams to explore the evolution of music through the influence across musical artists over time, by doing the following:
·Use the influence_data data set or portions of it to create a (multiple) directed network(s) of musical influence, where influencers are connected to followers. Develop parameters that capture ‘music influence’ in this network. Explore a subset of musical influence by creating a subnetwork of your directed influencer network. Describe this subnetwork. What do your ‘music influence’ measures reveal in this subnetwork?
·Use full_music_data and/or the two summary data sets (with artists and years) of music characteristics, to develop measures of music similarity. Using your measure, are artists within genre more similar than artists between genres?
·Compare similarities and influences between and within genres. What distinguishes a genre and how do genres change over time? Are some genres related to others?
·Indicate whether the similarity data, as reported in the data_influence data set, suggest that the identified influencers in fact influence the respective artists. Do the ‘influencers’ actually affect the music created by the followers? Are some music characteristics more ‘contagious’ than others, or do they all have similar roles in influencing a particular artist’s music?
·Identify if there are characteristics that might signify revolutions (major leaps) in musical evolution from these data? What artists represent revolutionaries (influencers of major change) in your network?
·Analyze the influence processes of musical evolution that occurred over time in one genre. Can your team identify indicators that reveal the dynamic influencers, and explain how the genre(s) or artist(s) changed over time?
·How does your work express information about cultural influence of music in time or circumstances? Alternatively, how can the effects of social, political or technological changes (such as the internet) be identified within the network?
Write a one-page document to the ICM Society about the value of using your approach to understanding the influence of music through networks. Considering the two problem data sets were limited to only some genres, and subsequently to those artists common to both data sets, how would your work or solutions change with more or richer data? Recommend further study of music and its effect on culture.
The ICM Society, an interdisciplinary and diverse group from the fields of music, history, social science, technology, and mathematics, looks forward to your final report.
Your PDF solution of no more than 25 total pages should include:
·One-page Summary Sheet.
·Table of Contents.
·Your complete solution.
·One-page document to ICM society.
·References list.
Note: New for 2021! The ICM Contest now has a 25-page limit. All aspects of your submission count toward the 25-page limit: Summary Sheet, Table of Contents, Main Body of Solution, Images and Tables, One-page Document, Reference List, and any Appendices.
Attachments
We provide the following four data files for this problem. THE DATA FILES PROVIDED CONTAIN THE ONLY DATA YOU SHOULD USE FOR THIS PROBLEM.
1.influence_data.csv
2.full_music_data.csv
3.data_by_artist.csv
4.data_by_year.csv Data Descriptions
1.influence_data.csv
(Data is encoded in utf-8 to allow for handling of special characters):
-influencer_id: A unique identification number given to the person listed as influencer. (string of digits)
-influencer_name: The name of the influencing artist as given by the follower or industry experts. (string)
-influencer_main_genre: The genre that best describes the bulk of the music produced by the influencing artist. (if available) (string)
-influencer_active_start: The decade that the influencing artist began their music career. (integer)
-follower_id: A unique identification number given to the artist listed as follower. (string of digits)
-follower_name: The name of the artist following an influencing artist. (string)
-follower_main_genre: The genre that best describes the bulk of the music produced by the following artist. (if available) (string)
-follower_active_start: The decade that the following artist began their music career. (integer)
2.full_music_data.csv 3. data_by_artist.csv 4. data_by_year.csv
Spotify audio features from the “full_music_data”, “data_by_artist”, “data_by_year”:
-artist_name: The artist who performed the track. (array)
-artist_id: The same unique identification number given in the influence_data.csv file. (string of digits)
Characteristics of the music:
-danceability: A measure of how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable. (float)
-energy: A measure representing a perception of intensity and activity. A value of 0.0 is least intense/energetic and 1.0 is most intense/energetic. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale. Perceptual features contributing to this attribute include dynamic range, perceived loudness, timbre, onset rate, and general entropy. (float)
-valence: A measure describing the musical positiveness conveyed by a track. A value of 0.0 is most negative and 1.0 is most positive. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry). (float)
-tempo: The overall estimated tempo of a track in beats per minute (BPM). In musical terminology, tempo is the speed or pace of a given piece and derives directly from the average beat duration. (float)
-loudness: The overall loudness of a track in decibels (dB). Values typical range between -60 and 0 db. Loudness values are averaged across the entire track and are useful for comparing relative loudness of tracks. Loudness is the quality of a sound that is the primary psychological correlate of physical strength (amplitude). (float)
-mode: An indication of modality (major or minor), the type of scale from which its melodic content is derived, of a track. Major is represented by 1 and minor is 0.
-key: The estimated overall key of the track. Integers map to pitches using standard Pitch Class notation. E.g. 0 = C, 1 = C♯/D♭, 2 = D, and so on. If no key was detected, the value for key is -1. (integer)
Type of vocals:
-acousticness: A confidence measure of whether the track is acoustic (without technology enhancements or electrical amplification). A value of 1.0 represents high confidence the track is acoustic. (float)
-instrumentalness: Predicts whether a track contains no vocals. “Ooh” and “aah” sounds are treated as instrumental in this context. Rap or spoken word tracks are clearly “vocal”. The closer the instrumentalness value is to 1.0, the greater likelihood the track contains no vocal content. Values above 0.5 are intended to represent instrumental tracks, but confidence is higher as the value approaches 1.0. (float)
-liveness: Detects the presence of an audience in a track. Higher liveness values represent an increased probability that the track was performed live. A value above 0.8 provides strong likelihood that the track is live. (float)
-speechiness: Detects the presence of spoken words in a track. The more exclusively speech- like the recording (e.g. talk show, audio book, poetry), the closer to 1.0 the attribute value. Values above 0.66 describe tracks that are probably made entirely of spoken words. Values between 0.33 and 0.66 describe tracks that may contain both music and speech, either in sections or layered, including such cases as rap music. Values below 0.33 most likely represent music and other non-speech-like tracks. (float)
-explicit: Detects explicit lyrics in a track (true (1) = yes it does; false (0) = no it does not OR unknown). (Boolean)
Description:
-duration_ms: The duration of the track in milliseconds. (integer)
-popularity: The popularity of the track. The value will be between 0 and 100, with 100 being the most popular. The popularity is calculated by algorithm and is based, in the most part, on the total number of plays the track has had and how recent those plays are. Generally speaking, songs that are being played more frequently now will have a higher popularity than songs that were played more frequently in the past. Duplicate tracks (e.g. the same track from a single and an album) are rated independently. Artist and album popularity are derived mathematically from track popularity. (integer)
-year: The year of release of a track. (integer from 1921 to 2020)
-release_date: The calendar date of release of a track mostly in yyyy-mm-dd format, however precision of date may vary and some just given as yyyy.
-song_title (censored): The name of the track. (string) Software was run to remove any potential explicit words in the song title.
-count: The number of songs a particular artist is represented in the full_music_data.csv file. (integer)
题目译文
2021年ICM
问题D:音乐的影响
音乐是人类社会的一部分,是文化遗产的重要组成部分。 作为理解音乐在人类集体经验中所扮演角色的努力的一部分,我们被要求开发一种方法来量化音乐进化。 当艺术家创作一首新音乐时,有许多因素可以影响他们,包括他们与生俱来的创造力、当前的社会或政治事件、获得新的乐器或工具的机会或其他个人经历。 我们的目标是了解和衡量以前制作的音乐对新音乐和音乐艺术家的影响。
一些艺术家可以列出十几个或更多的其他艺术家,他们说他们影响了他们自己的音乐作品。 还有人建议,影响可以用歌曲特征之间的相似程度来衡量,如结构、节奏或歌词。 音乐有时会发生革命性的变化,提供新的声音或节奏,例如当一个新的体裁出现时,或者有一个现有的体裁的重新发明(例如。 古典、流行/摇滚、爵士乐等。)。 这可能是由于一系列微小的变化,艺术家的合作努力,一系列有影响力的艺术家,或社会内部的转变。
许多歌曲有着相似的声音,许多艺术家为音乐流派的重大转变做出了贡献。 有时这些变化是由于一个艺术家影响另一个艺术家。 有时,它是针对外部事件(如重大世界事件或技术进步)而出现的变化)。 通过考虑歌曲网络及其音乐特征,我们可以开始捕捉音乐艺术家对彼此的影响。 也许,我们还可以更好地了解音乐是如何随着时间的推移在社会中演变的。
您的团队已经被整合集体音乐(ICM)协会确定,以开发一个衡量音乐影响的模型。 这个问题要求你研究艺术家和流派的进化和革命趋势。 为了做到这一点,ICM给了您的团队几个数据集:
1) “influence_data”1 代表音乐影响者和追随者,如艺术家自己报告的,以及行业 专家的意见。 这些数据包含了过去90年来5,854名艺术家的影响者和追随者。
2)“full_music_data”2 提供16个可变的条目,包括音乐特征,如舞蹈性,节
奏,响度和键,以及98,340首歌曲的artist_name和artist_id。 这些数据用于创建两个汇总数据集,包括:
a.艺术家“data_by_artist”的平均价值”,
b.意味着多年的“data_by_year”。
1 这些数据来自All Music.com
2 这些数据是从Spotify的API中获得的
注意:这些文件中提供的数据是较大数据集的子集。 这些文件包含了你要为这个问题使用的唯一数据。
为了实施这个具有挑战性的项目,ICM协会要求您的团队通过音乐艺术家随时间的影响来探索音乐的演变,具体做法如下:
·使用influence_data数据集或其部分创建一个(多个)有向网络的音乐影响,其中影响者连接到追随者。 开发在这个网络中捕获“音乐影响”的参数。 通过创建你的定向影响者网络的子网来探索音乐影响的子集。 描述这个子网。 你的“音乐影响”措施在这个子网中揭示了什么?
·使用full_music_data和/或两个汇总数据集(与艺术家和年份)的音乐特征,以制定音乐相似性的度量。 用你的衡量标准,流派中的艺术家是否比流派之间的艺术家更相似?
·比较体裁之间和体裁内部的相似性和影响。 一个体裁的区别是什么,体裁是如何随着时间的推移而变化的? 有些体裁与其他体裁有关吗?
·指出data_influence数据集中报告的相似性数据是否表明已识别的影响者实际上影响了各自的艺术家。 “影响者”真的会影响追随者创造的音乐吗? 有些音乐特征是否比其他音乐更具有“传染性”,或者它们在影响特定艺术家的音乐方面都有类似的作用?
·从这些数据中确定是否有可能意味着音乐进化的革命(重大飞跃)的特征? 什么艺术家代表革命者(重大变革的影响者)在你的网络?
·分析音乐演变的影响过程,随着时间的推移,在一个体裁。 你的团队能找出揭示动态影响者的指标,并解释流派或艺术家是如何随着时间的推移而变化的吗?
·你的作品如何在时间或环境中表达关于音乐文化影响的信息? 或者,如何在网络中识别社会、政治或技术变革(如互联网)的影响?
写一份一页的文件给ICM协会,关于使用你的方法来理解音乐通过网络的影响的价值。考虑到这两个问题数据集仅限于某些类型,然后是两个数据集共同的艺术家,您的工作或解决方案将如何随着更多或更丰富的数据而变化? 建议进一步研究音乐及其对文化的影响。
来自音乐、历史、社会科学、技术和数学领域的跨学科和多样化的ICM协会期待着您的最后报告。
您的PDF解决方案不超过25页,应包括:
·一页汇总表。
·目录。
·你的解决方案。
·提交ICM协会的一页文件。
·参考资料清单。
注:2021年新! ICM竞赛现在有25页的限制。 您提交的所有方面都按25页的限制计算: 摘要表、目录、解决方案主体、图像和表格、一页文档、参考列表和任何附录。
附件
我们为这个问题提供了以下四个数据文件。 提供的数据文件包含您应该用于此问题的唯一数据。
1.influence_data.csv
2.full_music_data.csv
3.data_by_artist.csv
4.data_by_year.csv数据描述
1.influence_data.csv
(数据以utf-8编码,以便处理特殊字符):
-influencer_id:给被列为影响者的唯一识别号码。 (一串数字)
-influencer_name:由追随者或行业专家给出的影响艺术家的名字。 (字符串)
-influencer_main_genre:最能描述影响艺术家创作的大部分音乐的体裁。 (如果可用)(字符串)
-influencer_active_start:影响艺术家开始音乐生涯的十年。 (整数)
-follower_id:给被列为跟随者的艺术家的唯一识别号码。 (一串数字)
-follower_name:跟随影响艺术家的艺术家的名字。 (字符串)
-follower_main_genre:最能描述以下艺术家创作的大部分音乐的体裁。 (如果可用)(字符串)
-follower_active_start:以下艺术家开始音乐生涯的十年。 (整数)
2.full_music_data.csv 3. data_by_artist.csv 4. data_by_year.csv
Spotify音频功能来自“full_music_data”、“data_by_artist”、“data_by_year”:
-artist_name:表演曲目的艺术家。 (数组)
-artist_id:influence_data.csv文件中给出的相同唯一标识号。 (一串数字)
音乐的特点:
-舞蹈性:一种基于音乐元素的组合,包括节奏、节奏稳定性、节拍强度和整体规律性,来衡量一个曲目是否适合跳舞。 值0.0是最不可跳舞的,1.0是最可跳舞的。
(浮动)
-能量:表示对强度和活动的感知的度量。 值0.0是最不强烈/能量的,1.0是最强烈/ 能量的。 通常,充满活力的轨道会感觉快速、响亮和嘈杂。 例如,死亡金属有很高的能量,而巴赫的前奏在量表上得分很低。 这一属性的感知特征包括动态范围、感知响度、音色、起跳率和一般熵。 (浮动)
-价态:一种描述曲目所传达的音乐积极性的度量。 值0.0最负,1.0最正。 高价音的轨道更积极(例如。 快乐,开朗,兴高采烈),而低价音轨听起来更消极(例如。 悲伤,沮丧,愤怒)。 (浮动)
-节奏:以每分钟节拍为单位的轨道的总体估计节奏(BPM)。 在音乐术语中,节奏是给定作品的速度或节奏,直接来源于平均节拍持续时间。 (浮动)
-响度:轨道的整体响度,单位为分贝(dB)。 值在-60到0db之间的典型范围。 响度值在整个轨道上是平均的,对于比较轨道的相对响度是有用的。 声音是声音的质量, 是身体力量(振幅)的主要心理关联)。 (浮动)
-模式:一种轨迹的情态(主要或次要)的指示,它的旋律内容是从其尺度的类型。主修用1表示,辅修用0表示。
-关键:估计轨道的总体关键。 整数映射到点,使用标准的Pitch类表示法。 E.g。0=C,1=C♯/D♭,2=D等等。 如果没有检测到键,则键的值为-1。 (整数)
唱腔类型:
-声学:衡量轨道是否声学(没有技术增强或电气放大)的置信度)。 值1.0表示高度置信,轨道是声学的。 (浮动)
-工具性:预测一个曲目是否包含没有声音。 在这种情况下,“呜”和“啊”的声音被视为工具。 说唱或口语曲目显然是“声乐”。 器乐值越接近1.0,曲目不包含声乐内容的可能性就越大。高于0.5的值意在表示工具轨道,但随着值接近1.0,置信度更高。 (浮动)
-活力:在赛道上检测观众的存在。 较高的活性值表示轨道被实时执行的概率增加。高于0.8的值提供了轨道运行的强烈可能性。 (浮动)
-言语:在一个轨道上检测口语的存在。 更纯粹的演讲就像录音(例如。 脱口秀,有声书,诗歌),属性值越接近1.0。 高于0.66的值描述了可能完全由口语构成的音轨。 值在0.33到0.66之间,描述可能包含音乐和语音的曲目,无论是在部分还是分层,包括说唱音乐。 低于0.33的值最有可能代表音乐和其他非语音类曲目。 (浮动)
-显式:检测曲目中的显式歌词(真(1)=是的;假(0)=不,它没有或未知)。 (布尔值)
说明:
-duration_ms:轨道的持续时间(毫秒。 (整数)
-流行:赛道的流行。 值将在0到100之间,其中100是最受欢迎的。 流行度是通过算法来计算的,在很大程度上是基于赛道上的总播放次数和最近的播放次数。 一般来说, 现在播放频率更高的歌曲将比过去播放频率更高的歌曲更受欢迎。 重复轨道(例如。同一曲目来自单一和专辑)是独立的。 艺术家和专辑的流行在数学上来源于曲目的流行。 (整数)
-年份:轨道发布的年份。 (1921年至2020年为整数)
-release_date:轨道发布的日历日期大多采用yyyy-mm-dd格式,但日期的精度可能会有所不同,有些只是作为yyyy给出的。
-song_title(审查):轨道的名称。 运行软件是为了删除歌曲标题中任何潜在的显式单词。
-计数:特定艺术家的歌曲数量表示在full_music_data.csv文件中。 (整数)
思路分析
题目要求:
(1)根据附件数据influence_data,构建音乐人之间的定向网络模型,或许会根据不同的音乐派别划分成多个子图,进而做出描述性分析与可视化;构建影响力指标表示音乐人的影响程度,可以参考复杂网络、聚类思想中的有向加权度指标。
(2)根据附件数据full_music_data 探讨不同流派音乐内部的相似性,可以参考聚类有效性评价指标DB、DUNN等,关键问题是需要我们构建相似性指标。
(3)分析不同类别音乐人或音乐之间的类内相似性差异,这些差异随时间是如何变化的,不同类别的音乐人或派系之间是否存在交互(文化背景等因素所导致)。
(4)分析不同派系的音乐中,影响者到连接者之间的影响力(Q1指标)是否存在明显差异或共性,如7种音乐特性与5种人声特征之间的规律。
(5)从数据中找出重大变革时间点,确定这些时间点的历史背景,确定主要的特征以更有效地表示这些飞跃,找出相关巨大贡献的艺术家。
(6)分析不同类型音乐随时间变化的影响过程(内部音乐人互相影响、外部不同派系音乐之间的影响)。提出综合指标来表示这种影响随时间的变化模式。
(7)该小问较难,一种可行的建议是从音乐人的作品数据(歌曲名、歌词等)中提取文本信息,获取主题词汇来表示时间、环境特征。
(8)模型推广。进一步研究模型的运行模式,以适用于更丰富的音乐数据集等。
结合一篇论文分析(论文来源于网络,侵删)
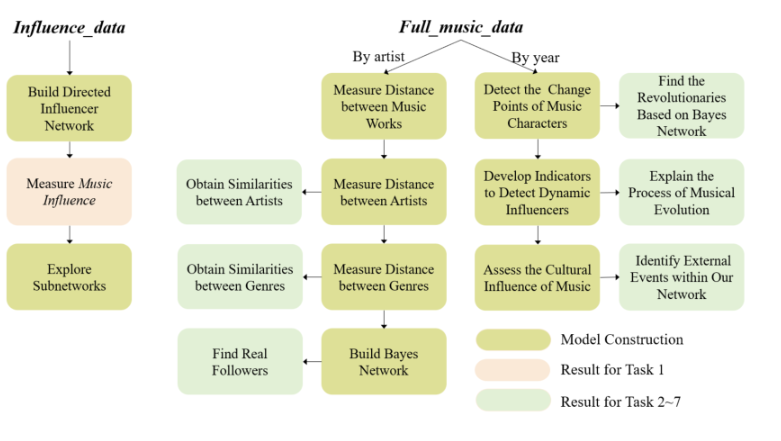
任务1
将influencers和fllowers视为结点,构建网络,涉及5603个艺术家和42770个影响(数据集:influence——data.csv)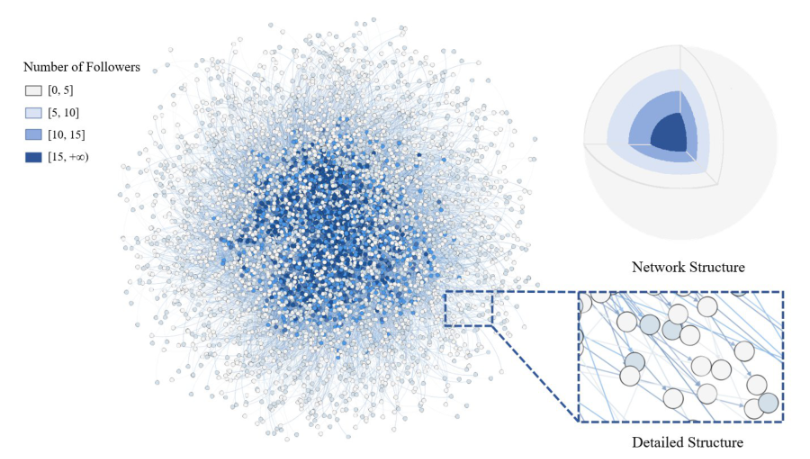
子图筛选出10个顶级艺术家以及每一位艺术家与其追随者相连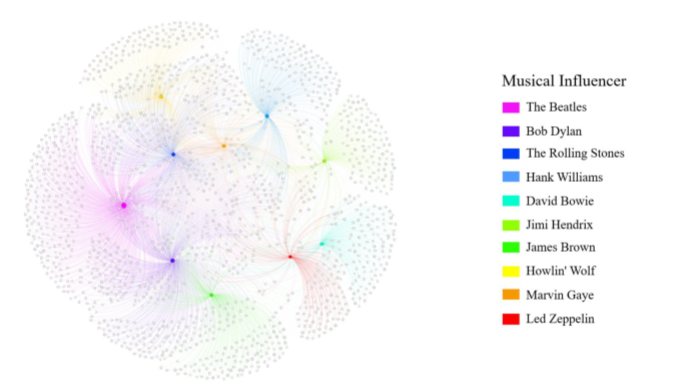
在影响者和跟随者之间建立了一个有向网络,基于网络理论,提出了三种不同的度量——度中心性、加权度中心性和特征中心性。然后,开发了这些指标的组合,作为音乐影响的综合。之后,创建了一个子网来说明影响力。
任务2
进行数据清洗,删除违背常识的变量
一些音乐特征具有相似的含义,例如“能量”和“响度”都反映了音轨的强度和活动,为了减少相似度计算时的共线性的影响,使用主成分分析(PCA)来减少数据的离散度,同时尽可能保持数据的变化。
在主成分分析结果的基础上,选择前7个主成分,忽略REST,新的7个变量保持了80%以上的原始数据信息。
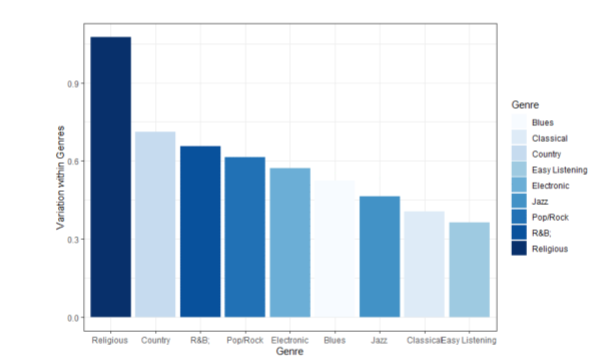
首先利用主成分分析对数据进行降维和共线性处理,然后定义和计算不同路径之间的距离,以获得艺术家之间的相似性。通过计算平均相似度,采用Mann-Whitney检验.结果表明,在概率为62.8%,p值小于0.001的情况下,某一体裁中的艺术家比体裁之间的艺术家更相似。
所有艺术家之间的相似性如图所示。Mann-Whitney的统计数据显示,以62.8%的概率和小于0.001的p值,流派中的艺术家比流派之间的艺术家更相似。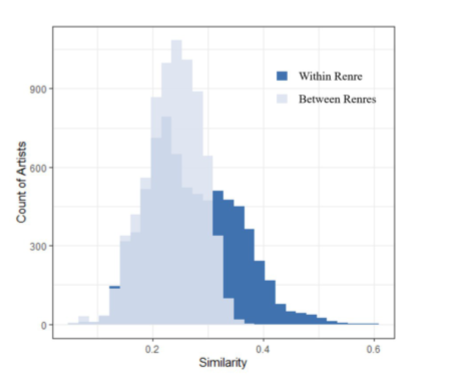
任务3
为了比较音乐的相似性和对体裁层次的影响,首先将数据集中的体裁合并为DataSet“datunce_data.csv”和数据集“data_by_artist.csv”,然后根据不同的类型对数据进行分组。
Figure 12 shows the Similarity Matrix and Influence Matrix between Genres. Blues andEasy Listening share some similar characteristics in musical features,whereas Electronic andVocal are more similar. As for influence, Pop/Rock significantly influences other genres. Interestingly, Pop/Rock has a strong influence on R&B, but they do not share significant similarityin musical characteristics, which we will discuss the reason later.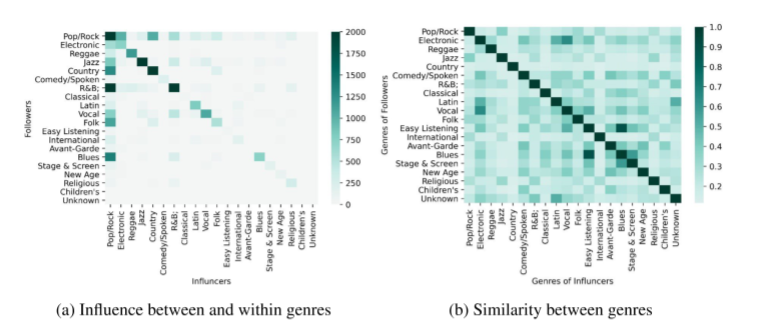
根据提出的音乐相似性度量, 发现在分析不同类型时,体裁内部和类型之间的相似性和影响差异很大。针对不同类型的不同类型,建立了体裁分类树模型。通过对不同时期影响因素的分析,探索了体裁的演化路径。基于类型尺度的定向网络,发现流行/摇滚与R&B、布鲁斯和民间有着很强的关系。
任务4
建立了一个基于音乐特征相似性的相似贝叶斯网络来识别真实的跟随者。然后,应用多元二样本法,发现没有强有力的证据(p值>0.1),任何音乐特征都比其他特征具有更强的“传染性”。
任务5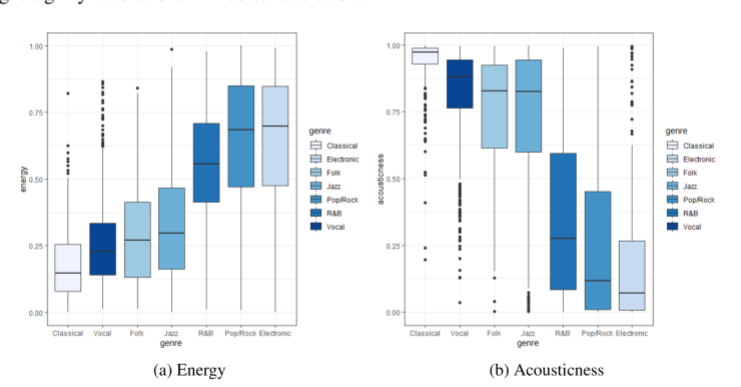
首先分析了流派的兴衰,发现了20世纪50年代的音乐革命。提出了一种动态规划算法,用于检测MUSIC特征中与革命相一致的变化点。结果表明,声学、能量、舞步能力和响度可能意味着革命。基于贝叶斯网络,Elvis Presley和Cliff Richard代表了革命者。
Our Similarity Bayesian Network is shown in figure.Elvis Presley, an influencer who hasthe most followers in 1950s in Pop/Rock, leads a countercultural movement in the United States.At the same time, Cliff Richard, an English artist, makes a dramatic change on the evolution ofthe genre. These two revolutionaries not only reinvent the existing genre, but also inspire artistslike Moti and Freestyle to create a new genre -Electronic.Therefore,Elvis Presley and CliffRichard represent revolutionaries in 1950s music revolution.
任务6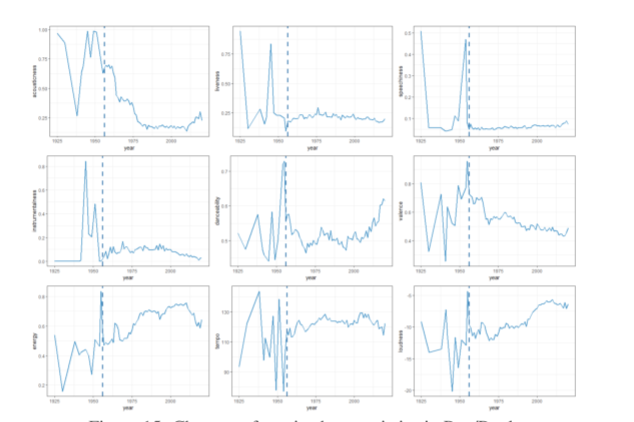
为了进一步了解流行音乐/摇滚的演变,提出了一种基于整个流派音乐特征滞后趋势的动态影响指示器。在1960年代到2010年代,有10位动态影响者,每个人对流行/摇滚都有自己独特的影响。此外,还解释了流行/摇滚的演变过程。
任务7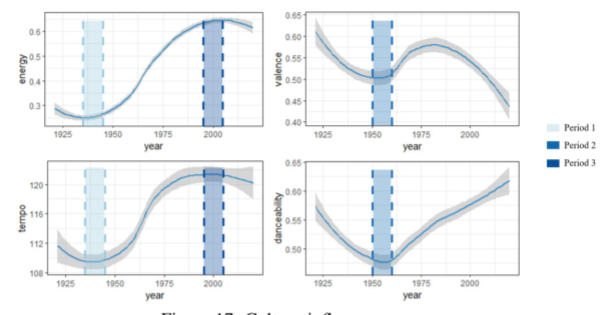
基于时间序列分析检测出三个重要时期,显示音乐对文化的影响。在所建立的模型基础上,确定了诸如文化运动的社会变化和互联网的扩散等技术变化。