猫狗大战案例介绍
1.迁移学习
2.Dataset数据集和TFRecord数据集的制作与应用
Cats vs. Dogs(猫狗大战)是Kaggle上的一个竞赛,利用给定的数据集,用算法实现猫和狗的识别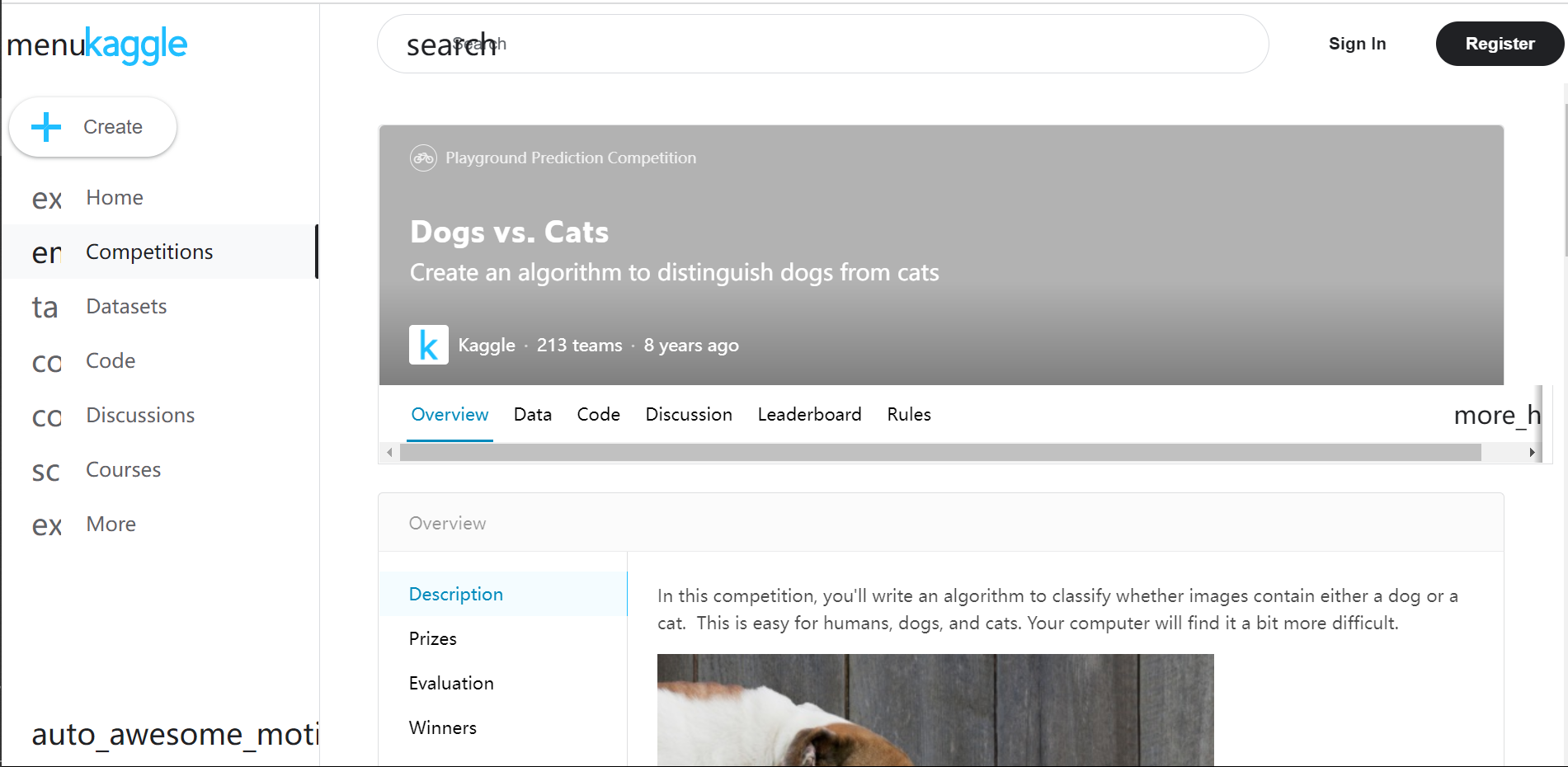
https://www.kaggle.com/c/dogs-vs-cats
tf.data.Dataset数据集
制作Dataset数据集
面对一堆格式不一的原始数据文件,数据预处理的过程往往十分繁琐,甚至比模型的设计还要耗费精力。
• 处理各种赃数据
• 设计 Batch 的生成方式
TensorFlow 提供了tf.data这一模块,包括了一套灵活的数据集构建API,能够帮助快速、高效地构建数据输入的流水线,尤其适用于大数据量场景。
tf.data.Dataset类是tf.data的核心,提供了对数据集的高层封装
tf.data.Dataset由一系列的可迭代访问的元素(element)组成,每个元素包含一个或多个张量
用 tf.data.Dataset.from_tensor_slices()是建立 tf.data.Dataset 的基本方法,适用于数据量较小(能够整个装进内存)的情况
Dataset数据集对象的预处理
tf.data.Dataset 类提供了多种数据集预处理方法,常用的包括:
• Dataset.map(f) 对数据集中的每个元素应用函数f
• Dataset.shuffle(buffer_size) 将数据集打散,实现乱序
• Dataset.batch(batch_size) 将数据集分成批次
• Dataset.prefetch() 预取出数据集中的size个元素
• Dataset.take () 截取数据集中的前size个元素
猫狗大战:Dataset数据集构建
确定样本图像的标签值:
·文件名包含分类标签信息
·不同类别的文件放不同的目录
数据读取
·定义数据读取函数
·定义解码图片和调整图片大小的函数——读取图片文件并解码,调整图片的大小并标准化
建立猫狗大战Dataset数据集
·读取图像数据并处理
·乱序——Dataset.shuffle(buffer_size) :将数据集打乱(设定一个固定大小的缓冲区(Buffer),取出前 buffer_size 个元素放入,并从缓冲区中随机采样,采样后的数据用后续数据替换)
·分批——Dataset.batch(batch_size):将数据集分成批次,即对每 batch_size 个元素,在第 0 维合并成为一个元素
定义准备Dataset数据集的函数
读取训练数据并处理
Dataset数据集的使用
把Dataset数据集转换为迭代器
显示一批样本的图像和标签
基于VGG16的迁移学习模型构建与应用
迁移学习
利用已经训练好的模型作为新模型训练的初始化的学习方式。
• 所需样本数量更少;
• 模型达到收敛所需耗时更短
• 比如:网络在Cifar-10数据集上迭代训练5000次收敛,将一个在Cifar-100上训练好的模型迁移至Cifar-10上,只需1000次就能收敛。
• 当新数据集比较小且和原数据集相似时
• 当算力有限时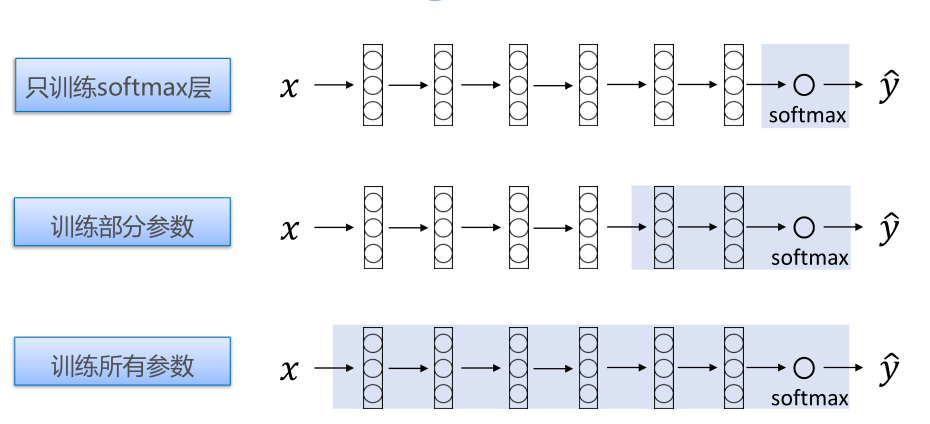
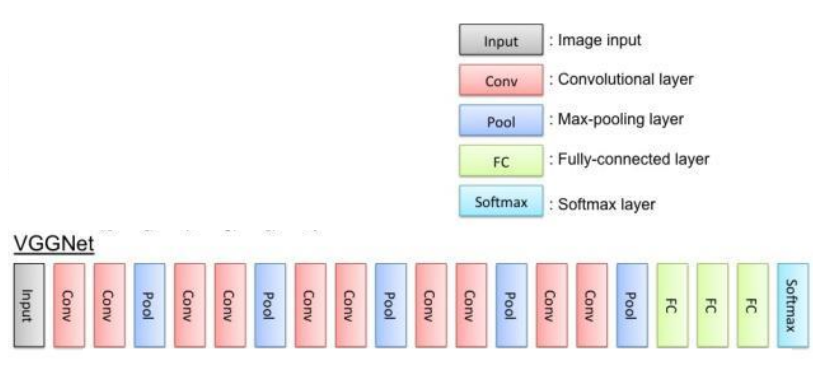
微调(finetuining)
(1) trainable参数变动
在进行Finetuning对模型重新训练时,对于部分不需要训练的层可以通过设置trainable=False来确保其在训练过程中不会被修改权值;
(2) 加上特定的全连接层
预训练的VGG是在ImageNet数据集上进行训练的,对1000个类别进行判定,若希望利用已训练模型用于其他分类任务,需要修改最后的全连接层。
编译模型
读取训练数据
模型训练
·定义超参数
·进行训练
模型存储
·需要安排pyyaml包,pip install pyyaml
·将模型结构和模型权重参数分开存储
应用模型
模型装载
·恢复模型的结构
·导入模型的权重参数
定义读取测试集图片的函数
定义预测函数
执行预测
TFRecord文件与应用
TFRecord
TFRecord 是 TensorFlow 中的数据集中存储格式。
将数据集整理成 TFRecord 格式后,TensorFlow 就可以高效地读取和处理这些数据集,从而更高效地进行大规模的模型训练。
TFRecord 可以理解为一系列序列化的 tf.train.Example 元素所组成的列表文件,而每一个 tf.train.Example 又由若干个 tf.train.Feature 的字典组成。
TFRecord格式数据文件处理过程
将形式各样的数据集整理为 TFRecord 格式,可以对数据集中的每个元素进行以下步骤:
1)读取该数据元素到内存;
2)将该元素转换为 tf.train.Example 对象(每一个 tf.train.Example 由若干个 tf.train.Feature 的字典组成,因此需要先建立 Feature 的字典);
3)将该 tf.train.Example 对象序列化为字符串,并通过一个预先定义的 tf.io.TFRecordWriter 写入 TFRecord 文件。
读取 TFRecord 数据可按照以下步骤:
1)通过 tf.data.TFRecordDataset 读入原始的 TFRecord 文件(此时文件中的 tf.train.Example 对象尚未被反序列化),获得一个 tf.data.Dataset 数据集对象;
2)通过 Dataset.map 方法,对该数据集对象中的每一个序列化的 tf.train.Example 字符串执行 tf.io.parse_single_example 函数,从而实现反序列化。
读取数据集的图片文件名列表及标签
定义生成TFRecord格式数据文件函数
TFRecord格式
tf.train.Feature 支持三种数据格式:
· tf.train.BytesList :字符串或原始 Byte 文件(如图片),通过 bytes_list 参数传入一个由字符串数组初始化的 tf.train.BytesList 对象;
· tf.train.FloatList :浮点数,通过 float_list 参数传入一个由浮点数数组初始化的 tf.train.FloatList 对象;
· tf.train.Int64List :整数,通过 int64_list 参数传入一个由整数数组初始化的 tf.train.Int64List 对象。
如果只希望保存一个元素而非数组,传入一个只有一个元素的数组即可。
生成TFRecord格式数据文件
定义TFRecord数据文件解码函数
定义读取TFRecord文件,解码并生成Dataset数据集的函数
读取TFRecord文件,解码并生成Dataset数据集